
What are the main Cloud Design Patterns?
and how they help fighting with fallacies of Distributed Computing

As software engineers building distributed systems, we often encounter challenges like unreliable networks, latency issues, and security concerns. The "Fallacies of Distributed Computing" describes common misconceptions that can lead to system failures if unaddressed. But recognizing these pitfalls is just the beginning. The real question is: how do we effectively overcome them?
That's where Cloud Design Patterns come into play. These patterns offer practical solutions to the challenges inherent in distributed computing. This article will explore essential Cloud Design Patterns across data management, design, messaging, security, and reliability.
Using these patterns allows you to navigate the complexities of distributed systems without falling prey to common mistakes.
So, let’s dive in.
Catio: Your Copilot for Tech Architecture (Sponsored)
Overcome the pitfalls of distributed computing with Catio, the trusted platform for real-time observability, 24/7 AI-driven recommendations, including design patterns tailor-fit for you, and data-backed decision insights. Join CTOs, architects, and tech teams in confidently building resilient, scalable cloud systems using Catio. Ready to optimize your architecture with Catio as a copilot? Learn More at Catio.tech

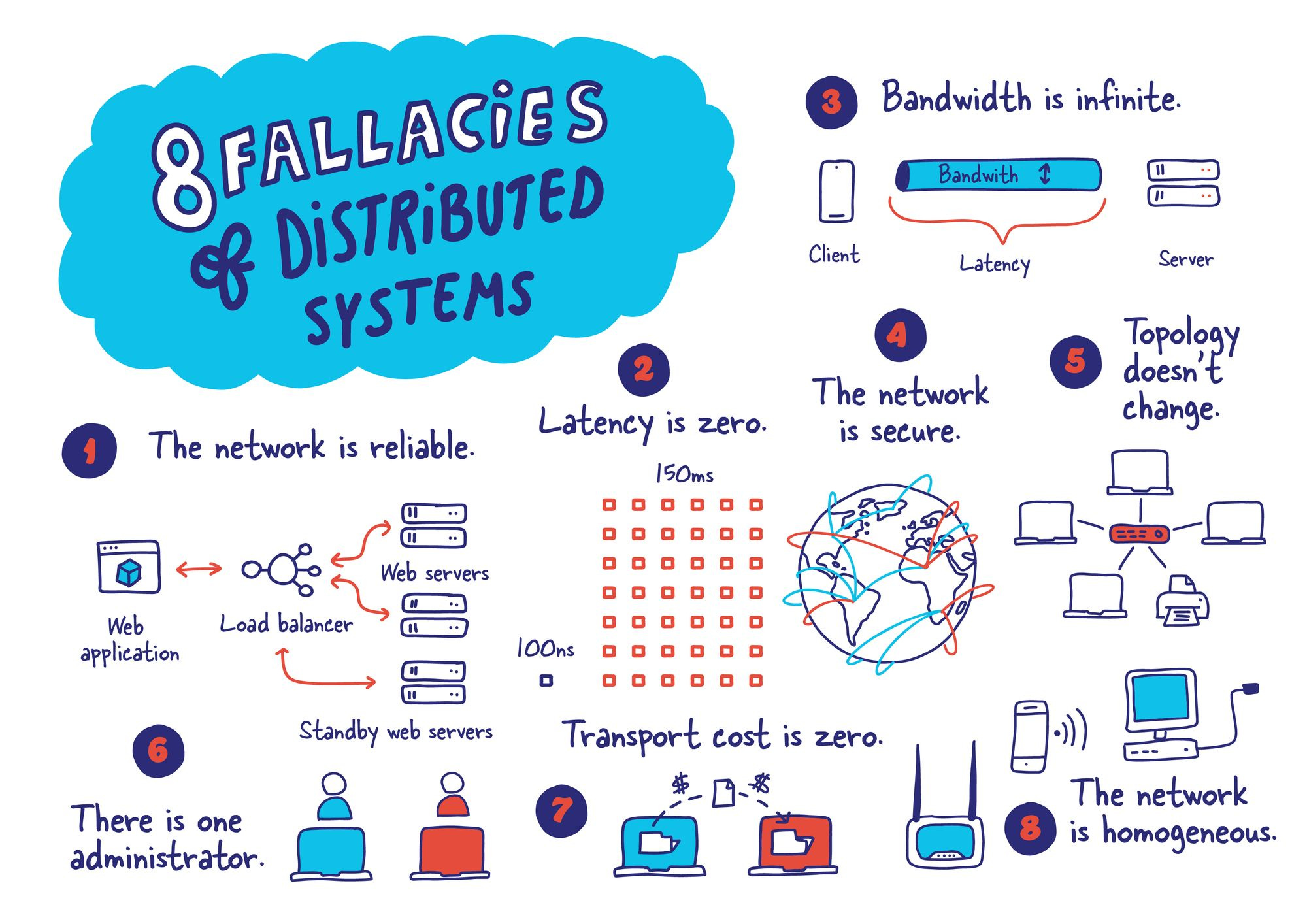
Fallacies of Distributed Computing
As software engineers, we often architect systems that span multiple servers, data centers, or even continents. Distributed computing has become the backbone of modern applications, enabling scalability and resilience that were once unimaginable. However, despite its ubiquity, common misconceptions—are known as the "Fallacies of Distributed Computing."
Peter Deutsch and others at Sun Microsystems made a collection of "Fallacies of Distributed Computing" claims to illustrate the erroneous presumptions that programmers unfamiliar with distributed applications frequently make.
What we often see with the creation of microservice architectures is that these fallacies should be addressed.
Here is the list of fallacies:
The network is reliable. This is the most critical fallacy. Networks are inherently unreliable and prone to outages, delays, and malicious attacks. Distributed systems must be designed to handle these inevitable hiccups gracefully.
➡️ Example: A microservices application may fail if it doesn't gracefully handle network timeouts, causing service failures.
Latency is zero. Every action reacts, and distributed systems are no exception. Messages take time to travel, and computations take time to complete. Ignoring latency can lead to performance bottlenecks and unpredictable behavior.
➡️ Example: A real-time analytics platform may deliver outdated insights if it doesn't account for data transmission delays.
Bandwidth is infinite. While bandwidth constantly increases, it's not unlimited. Distributed systems often generate massive amounts of data, and underestimating bandwidth constraints can lead to slowdowns and congestion.
➡️ Example: Streaming high-resolution video without compression can overwhelm network resources, leading to buffering and delays.
The network is secure. Your data is not invincible because it is spread across many machines. Distributed systems offer a larger attack surface, and security considerations must be woven into the very fabric of the design.
➡️ Example: Transmitting sensitive data over an unsecured network can result in data interception by malicious actors.
Topology doesn’t change. Networks are dynamic entities, constantly evolving as nodes are added, removed, or reconfigured. Distributed systems need to adapt to these changes without skipping a beat.
➡️ Example: A fixed IP address in configuration files can cause service disruptions if servers are moved or readdressed.
There is one administrator. In the real world, distributed systems often span many administrative domains. Understanding and coordinating across these boundaries is essential for smooth operation.
➡️ Example: Inconsistent firewall rules between departments can create security gaps or connectivity issues.
The transport cost is zero. However, sending data across a network isn't free. Each hop incurs a cost, both in time and resources. Optimizing data transfer is crucial for efficient distributed systems.
➡️ Example: Excessive API calls in a cloud service can inflate costs due to data egress fees.
The network is homogeneous, and different networks have different characteristics. What works on a local network might translate poorly to the global Internet. Distributed systems need to be flexible and adaptable to diverse network environments.
➡️ Example: An application optimized for high-speed wired connections may perform poorly on mobile networks.
Understanding these fallacies is the first step toward building reliable distributed systems, but also:
Design systems with redundancy and fault tolerance.
Put monitoring and alerting systems in place.
Rank security best practices and data encryption.
Optimize communication protocols for efficiency and performance.
Choose technologies and architectures suited to the specific needs of the system.
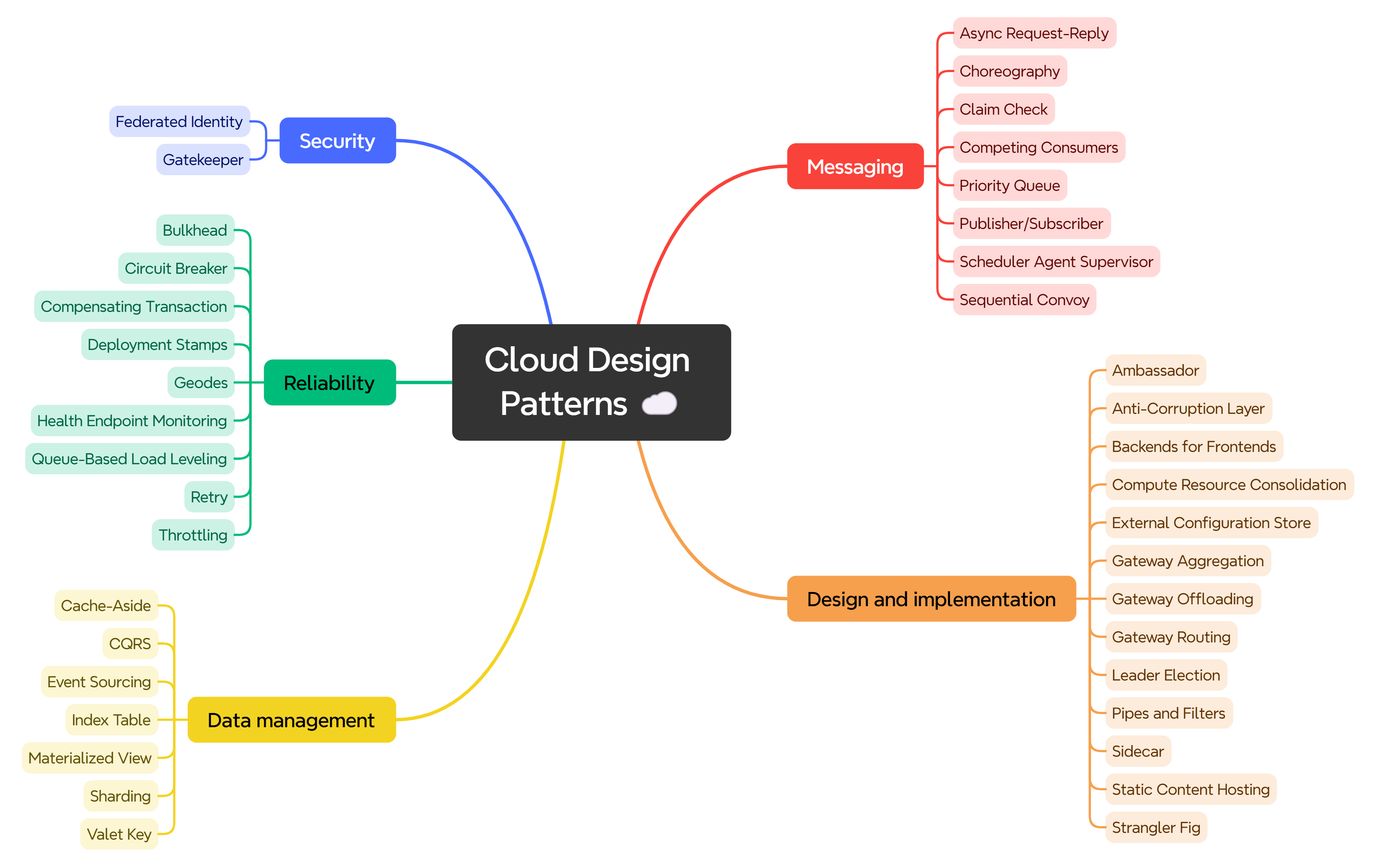
Cloud Design Patterns ☁️
These design principles can be used to create dependable, scalable, and secure cloud systems. Most cloud workloads are prone to the fallacies of distributed computing, so these patterns raise awareness and mitigate them, including trade-offs.
We can group Cloud Design Patterns into three general groups. Each pattern can be applied to any distributed system, whether hosted on-prem or cloud platform.
The main Cloud Design Pattern groups are:
1. Data Management 📊
The main component of cloud applications is data management, which affects most of the quality criteria. Data is hosted across many servers and locations for performance, scalability, or availability. This could pose several difficulties. For instance, data synchronization between many places is often required to ensure data consistency.
The most important patterns in this group are:
Cache-Aside Pattern. Improve application performance and reduce the load on data stores by caching frequently accessed data.
Command and Query Responsibility Segregation (CQRS) Pattern. Separate read and write operations to optimize performance, scalability, and security.
Event Sourcing Pattern. Maintain a complete history of changes to an application's data.
Materialized View Pattern. Improve query performance by precomputing and storing the results of complex queries.
Sharding Pattern. Scale data storage by partitioning data across multiple databases or servers.
2. Design and Implementation 🛠️
Good design includes maintainability to facilitate administration and development, reusability to allow components and subsystems to be used in various applications and contexts, and consistency and coherence in component design and deployment. Decisions made during the design and implementation phase influence the quality and total cost of ownership of cloud-hosted applications and services.
The most essential patterns in this group are:
Strangler Fig Pattern. Gradually migrate a legacy system by replacing specific pieces with new applications or services.
Anti-Corruption Layer Pattern. This pattern protects a new system's integrity when integrating legacy or external systems with different models or paradigms.
Bulkhead Pattern. Increase system resilience by isolating failures in one component from affecting others.
Sidecar Pattern: Deploy a parallel component to extend or enhance a service's functionality without modifying its code.
The Backends for Frontends (BFF) Pattern involves creating separate backend services tailored to the needs of different client applications (e.g., web and mobile).
3. Messaging 📨
Because cloud applications are distributed, a messaging infrastructure is needed to link the various parts and services. This infrastructure should be loosely coupled to allow for the largest scalability. Asynchronous messaging is popular and has many advantages but drawbacks, like sorting messages, managing poison messages, idempotency, and more.
The most essential patterns in this group are:
Queue-Based Load Leveling Pattern. Manage varying workloads by buffering incoming requests and ensuring your system can handle load fluctuations smoothly.
Publisher-Subscriber Pattern. Enable an application to broadcast messages to multiple consumers without being tightly coupled to them.
Competing Consumers Pattern. Enhance scalability and throughput by having multiple consumers process messages concurrently.
Message Broker Pattern. Decouple applications by introducing an intermediary that handles message routing, transformation, and delivery.
Pipes and Filters Pattern. Process data through a sequence of processing components (filters) connected by channels (pipes).
4. Security 🔒
Security protects information systems from hostile attacks by ensuring data confidentiality, integrity, and availability. Losing these guarantees might harm your company's operations, earnings, and reputation in the marketplace. Following accepted procedures and remaining watchful to spot and address vulnerabilities and active threats are necessary for maintaining security.
The most essential patterns in this group are:
Valet Key Pattern. Provide clients with secure, temporary access to specific resources without exposing sensitive credentials.
Gatekeeper Pattern. Protect backend services by validating and sanitizing requests through a dedicated host acting as a gatekeeper.
Federated Identity Pattern. Simplify user authentication by allowing users to log in with existing credentials from trusted identity providers.
Secret Store Pattern. Securely manage sensitive configuration data such as passwords, API keys, and connection strings.
Validation Pattern. Protect applications by ensuring all input data is validated and sanitized before processing.
5. Reliability ⚙️
When we say reliability, we usually mean the system's availability and resiliency. The percentage of time a system is operational and operating is called availability, expressed as a percentage of uptime. In contrast, a system's resilience is its capacity to handle and bounce back from purposeful and unintentional failures.
The most essential patterns in this group are:
Retry Pattern. Handle transient failures by automatically retrying failed operations to increase the chances of success.
Circuit Breaker Pattern. This pattern prevents an application from repeatedly trying to execute an operation that is likely to fail, protecting system resources and improving stability.
Throttling Pattern. Control the consumption of resources by limiting the rate at which an application processes requests.
Health Endpoint Monitoring Pattern. Detect system failures proactively by exposing health check endpoints that monitoring tools can access.
Check the complete list of Cloud Design Patterns on Azure and AWS.
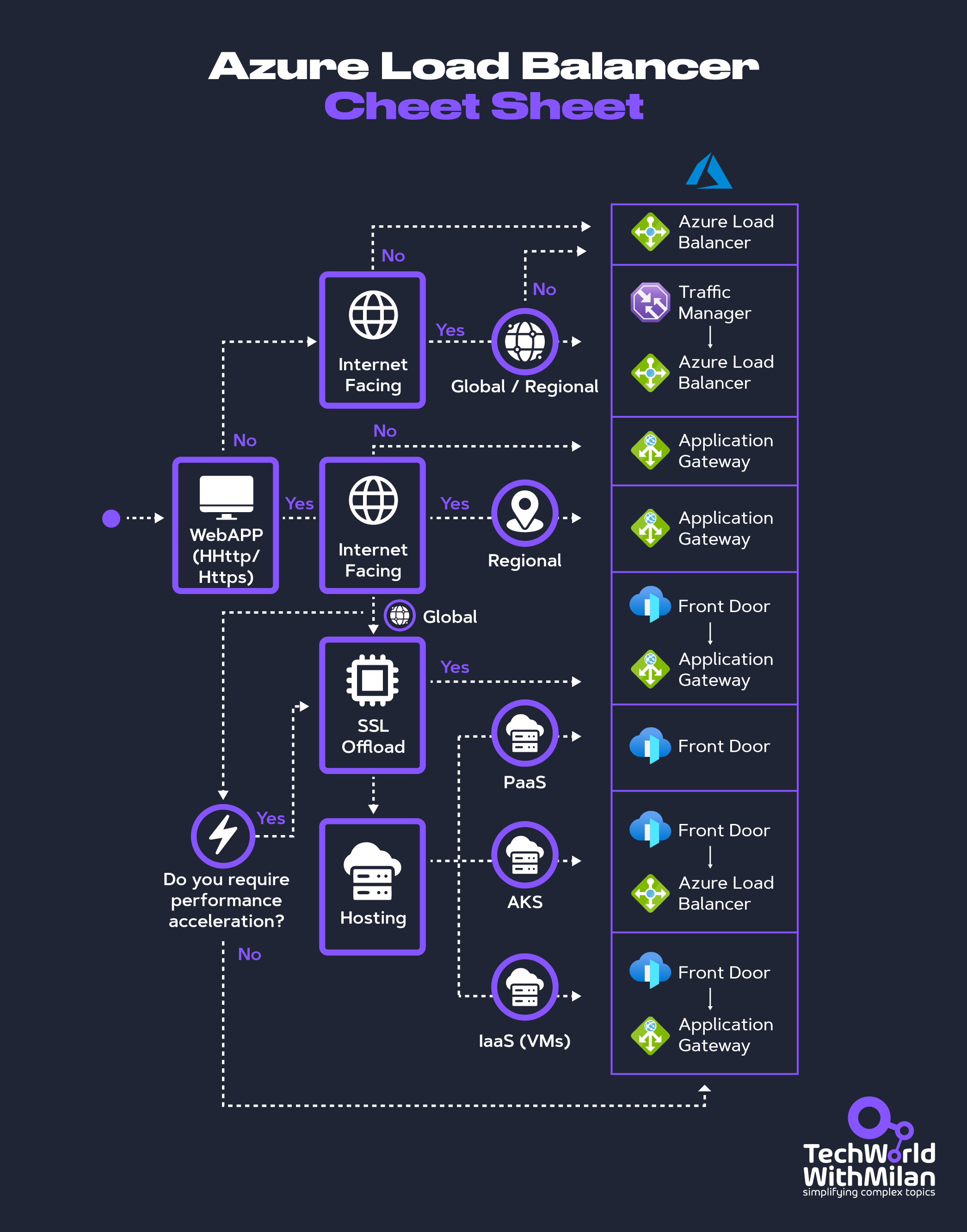
Bonus: Load-balancing options in Azure
It is crucial to ensure that applications can handle high traffic and always remain available. Load balancing is an important strategy for achieving this, and Azure offers several robust load-balancing solutions tailored to different needs.
Understanding Azure's load-balancing options can help you design scalable and resilient architectures, whether you're developing a simple cloud application or a complex system.
Key Azure Services for load balancing are:
Azure Front Door: A global load balancer that provides application acceleration and global load balancing at Layer 7 (HTTP/HTTPS). It optimizes routing based on performance and can handle SSL offloading.
Azure Traffic Manager: A DNS-based traffic load balancer that distributes traffic across multiple regions. It supports various routing methods such as geographic, performance, and priority-based routing, ensuring users are directed to the most appropriate regional endpoint.
Azure Load Balancer: A Layer 4 load balancer distributes traffic across a region's virtual machines (VMs). It supports both inbound and outbound scenarios, providing high availability and low latency for regional deployments.
Azure Application Gateway: is a Layer 7 load balancer with advanced routing capabilities, SSL termination, and a Web Application Firewall (WAF). It's tailored for web applications requiring regional load balancing.
Azure load-balancing services can be categorized along two dimensions: global versus regional and HTTP(S) versus non-HTTP(S).
Global vs Regional Load Balancing
1. Global Load Balancing 🌍 is designed to distribute traffic across multiple regions, enhancing availability, performance, and redundancy. It ensures that users are directed to the nearest or most optimal regional deployment, minimizing latency and improving user experience.
Services to use: Azure Front Door or Azure Traffic Manager.
➡️ Use cases:
Applications with users spread across multiple geographic regions.
Scenarios require disaster recovery and failover capabilities.
Improving application performance by reducing latency through regional routing.
2. Regional Load Balancing 📍 focuses on distributing traffic within a specific Azure region. It's ideal for scenarios where the application is hosted in a single region or when managing traffic across multiple services within that region.
Services to use: Azure Load Balancer or Azure Application Gateway.
➡️ Use cases:
Internal applications within a virtual network.
Web applications with advanced routing needs are hosted within a single region.
Load balancing across services within the same region for high availability.
HTTP(S) vs. Non-HTTP(S) Load Balancing
1. HTTP(S) Load Balancing 🔒 operates at Layer 7 and is designed to handle web traffic. It provides advanced routing capabilities based on URL paths, host headers, and more. These services are optimized for web applications, offering features like SSL offloading and web application firewalls.
Services to use: Azure Front Door or Azure Application Gateway.
➡️ Use cases:
Web applications requiring complex routing rules.
Securing web traffic with SSL/TLS and WAF.
Optimizing web application performance through caching and compression.
2. Non-HTTP(S) Load Balancing 🖧 operates at Layer 4 and is used for general-purpose traffic, such as TCP and UDP. These services are suitable for scenarios where low-level network traffic management is required.
Services to use: Azure Load Balancer or Azure Traffic Manager.
➡️ Use cases:
Applications requiring low-level traffic management, such as database servers or file transfers.
Non-web applications that use TCP or UDP protocols.
Balancing load for backend services and internal applications.
When you try to create a load balancer in Azure, you will be guided through a decision tree.
Also, check out this flowchart, which will help you choose a load-balancing solution for your application. The flowchart guides you through critical decision criteria to reach a recommendation.
More ways I can help you
LinkedIn Content Creator Masterclass ✨. In this masterclass, I share my proven strategies for growing your influence on LinkedIn in the Tech space. You'll learn how to define your target audience, master the LinkedIn algorithm, create impactful content using my writing system, and create a content strategy that drives impressive results.
Resume Reality Check" 🚀. I can now offer you a new service where I’ll review your CV and LinkedIn profile, providing instant, honest feedback from a CTO’s perspective. You’ll discover what stands out, what needs improvement, and how recruiters and engineering managers view your resume at first glance.
Promote yourself to 35,000+ subscribers by sponsoring this newsletter. This newsletter puts you in front of an audience with many engineering leaders and senior engineers who influence tech decisions and purchases.
Join My Patreon Community: This is your way of supporting me, saying “thanks, " and getting more benefits. You will get exclusive benefits, including all of my books and templates on Design Patterns, Setting priorities, and more, worth $100, early access to my content, insider news, helpful resources and tools, priority support, and the possibility to influence my work.
1:1 Coaching: Book a working session with me. 1:1 coaching is available for personal and organizational/team growth topics. I help you become a high-performing leader and engineer 🚀.
a comprehensive article! thank a lot.