Building APIs is one of the most important tasks for developers in modern engineering. These APIs allow different systems to communicate and exchange data. While REST has been the de facto standard for implementing APIs for many years, new emerging standards, such as gRPC and GraphQL, are available today.
This issue will discuss gRPC, GraphQL, and REST API architectures. We will determine each one's advantages and disadvantages and which tooling can be used.
What is an API?
The "Application Programming Interface" (API) is a communication channel between various software services. Applications that transmit requests and responses are called clients and servers, respectively. An API is an external software component that makes program functionality available to other programs.
In the honey bee 🐝 illustration below, the flower serves as the server, the hive serves as the client, and the bee provides the means of communication (REST API request).
What is an API? (Credits: Rapid API)
Different API architectures or protocols exist, such as REST, gRPC, and GraphQL.
Why is gRPC important?
gRPCis a high-performance, open-source, universal remote procedure call (RPC) framework developed by Google. It uses Protocol Buffers (protobuf) as its interface definition language. Protocol buffers are a very effective and quick way to serialize data over a network. This technology implements an RPC API using the HTTP 2.0 protocol; however, neither the server nor the API developer can access HTTP. It follows a client-response communication model, which supports bidirectional communication and streaming due to gRPC's ability to receive multiple requests from several clients and handle them simultaneously. Yet, gRPC is still quite limited when it comes to browser support.
As mentioned, gRPC uses Protocol Buffers by default to serialize payload data. Protocol Buffers are compact binary serialization formats for structured data. Using a schema defined in .proto files, they allow for efficient encoding and decoding across various languages. They offer advantages like smaller size and faster processing than traditional JSON or XML.
Advantages of gRPC:
Speed. Thanks to HTTP/2, gRPC is faster and more efficient than REST over HTTP/1.1.
Polyglot. Provides tools to generate client and server code in many languages.
Streaming: Supports bidirectional streaming, allowing for more interactive real-time communication.
Deadlines/Timeouts: Built-in support ensures requests don't hang. It automatically solves retries, network issues, etc.
Ecosystem: Supports authentication, load balancing, etc.
Drawbacks of gRPC:
Complex: An understanding of Protocol Buffers and the gRPC API is required. A schema must also be defined upfront.
Limited Browser Support: Native browser support is limited due to reliance on HTTP/2.
Tooling: While growing, gRPC tooling is less mature than REST's. You can use gRPCurl or Postman to test such APIs.
Not human-readable: As they are binary, it's difficult to debug as you can with text-based formats (such as XML or JSON).
gRPC
What are Protocol Buffers?
Protocol Buffers, often abbreviated as Protobuf, are a method devised by Google in 2008. for serializing structured data, similar to XML or JSON, but they're leaner and faster as they are binary, making them a go-to for applications that communicate with servers or store data efficiently.
Data serialization with Protocol Buffers involves a few steps:
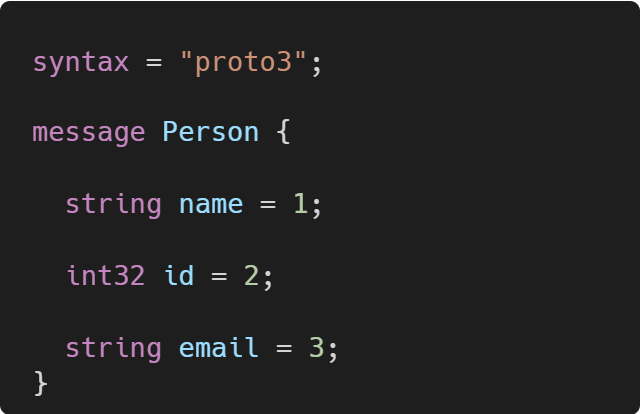
Define Data Structure: You start by defining the structure of your data in a .proto file. This includes specifying the types of data (integers, strings, booleans, custom types, etc.) and their field numbers.
For example:
Generate Source Code: Use the Protocol Buffers compiler (protoc) to generate source code in your desired language from the .proto file. The compiler can generate code for a variety of languages including Java, C++, Python, and more.
Generate executable package: The executable package is also generated and deployed with the source files produced by the Protobuf code. Messages are serialized and compressed in binary format at runtime..
Deserialization: When the recipient receives a serialized data stream, they can easily convert it back into a structured format using the generated classes.
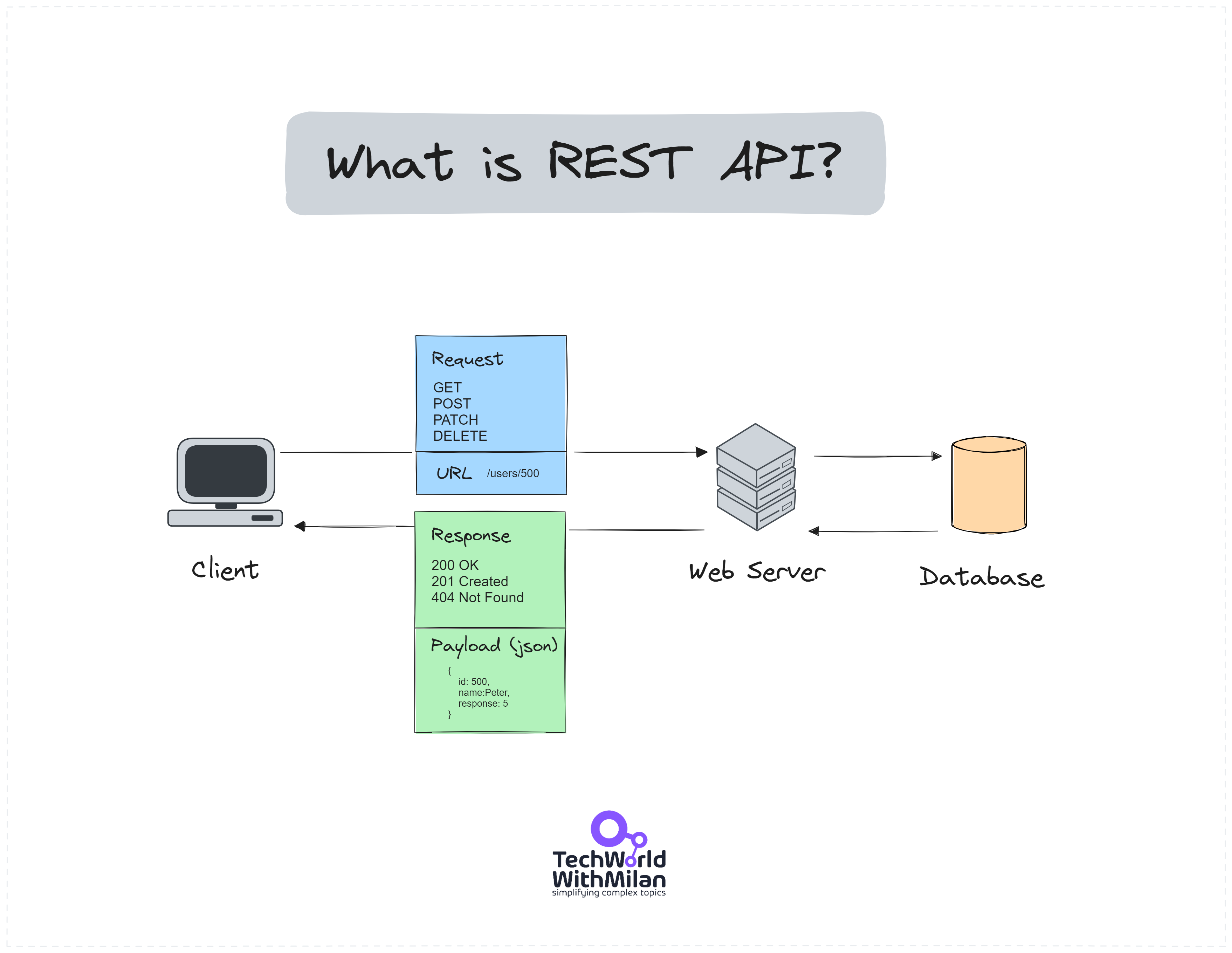
REST (Representational State Transfer) is not a framework or a library but an architectural style for building web services and APIs. In REST, everything is a resource identified by a unique URL, and these resources are manipulated using HTTP methods such as GET (to retrieve a resource), POST (to create a new resource), PUT or PATCH (to update a resource), and DELETE (to remove a resource).
Each request from client to server must contain all the information needed to understand and complete the request. The server does not store client context between requests, simplifying design and improving scalability. The client and server's HTTP request and response bodies carry JSON or XML representations of a resource's status.
Benefits of REST APIs:
Simplicity: Using standard HTTP methods and common data formats makes REST APIs easy to understand and implement.
Interoperability: REST APIs promote interoperability as different applications can interact seamlessly regardless of the programming languages or platforms used.
Scalability: The stateless nature of REST APIs allows for easy scaling to handle large volumes of requests.
Flexibility: REST APIs can be adapted to various use cases due to their versatile design principles.
Drawbacks of REST APIs:
Statelessness: REST relies on stateless transactions, meaning each request must complete all the information independently. This can be cumbersome for workflows that require maintaining state across multiple requests, like shopping carts on e-commerce sites.
Limited payload size: Data transfer in REST often happens through JSON or XML payloads, which can become quite large if you're dealing with complex data or many queries. This can lead to performance issues.
Lack of discoverability: REST APIs don't inherently make it easy for users to understand what functionality they provide or how to interact with them, which can add complexity for new users.
Performance for complex queries: REST might not be ideal for retrieving specific data points from a larger resource. Other options, like GraphQL, can be more efficient in such cases.
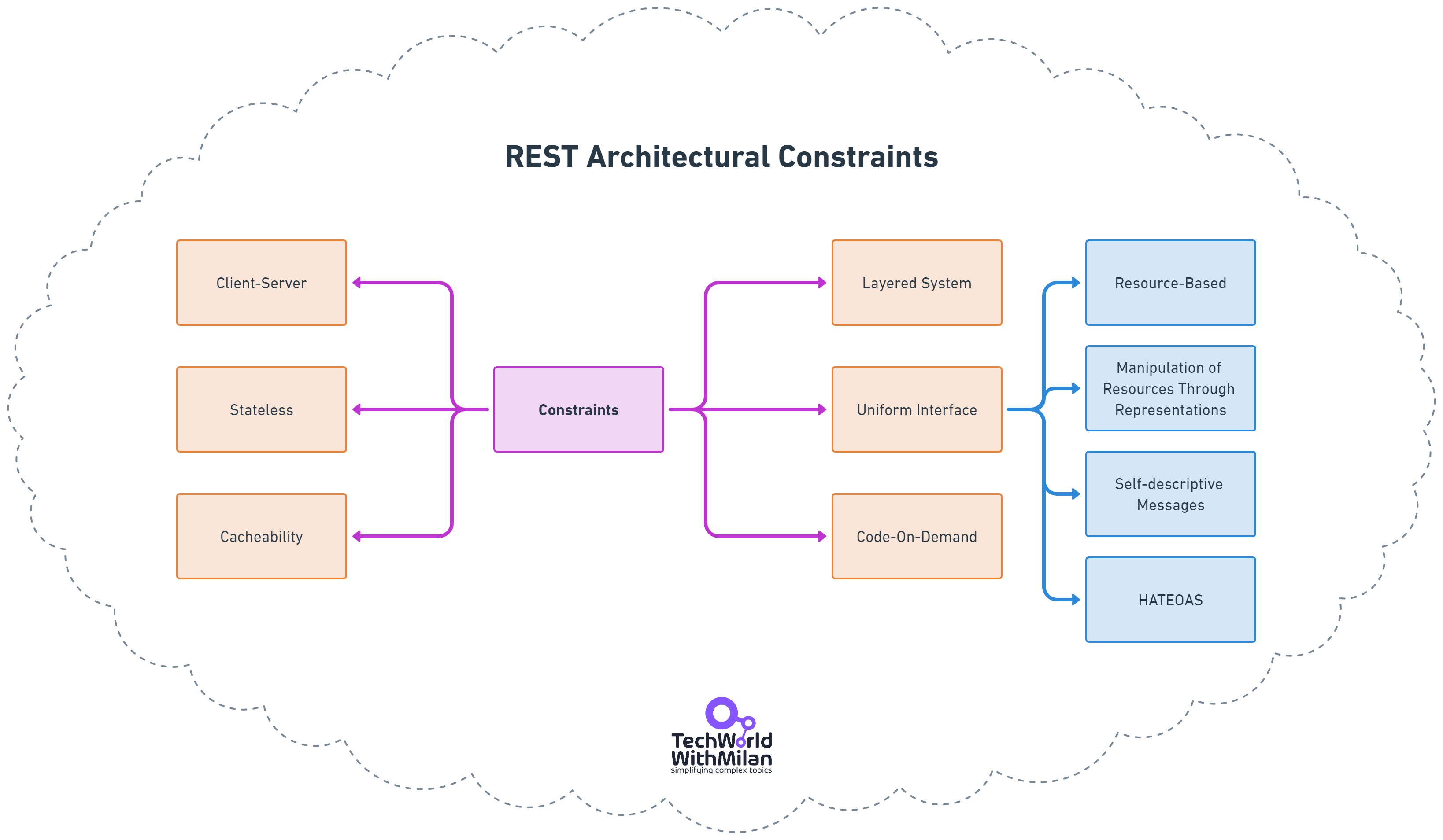
REST defines six architectural constraints an API should follow to be considered genuinely RESTful:
Client-Server: This separation of concerns separates the client (the application using the API) from the server (the application providing the API). The client initiates requests, and the server processes them and sends responses.
Stateless: Each request from the client to the server must contain all the information necessary to understand the request. The server doesn't store any context about the client between requests. This simplifies communication and improves scalability.
Uniform Interface: This constraint defines a set of rules for how clients interact with the server. These rules include:
Resource-based: APIs expose resources that clients can interact with. URLs identify resources.
Standard methods: Clients use standard HTTP methods (GET, POST, PUT, DELETE) to perform operations on resources.
Representation: Data is exchanged between client and server in a standard format like JSON or XML.
Cacheable: The client may mark server responses as cacheable. This allows clients to store frequently accessed data locally, reducing server load and improving performance.
Layered System: The architecture may consist of multiple layers (proxies, caches, load balancers) between the client and server. These layers can improve performance, security, and scalability.
Code on Demand (Optional): While not strictly mandatory, a RESTful API may optionally transfer executable code to the client. Clients can use this code to extend its functionality or process data locally.
REST Architectural Constraints
An example of a REST API call for the API on the https://api.example.com address when we want to get the info about the user with ID 500 is the following by using curl command-line tool: curl -X GET https://api.example.com/users/500 -H "Accept: application/json". The last part (Accept: application/json) is a header that indicates that the client expects to receive the data in JSON format. A response would be the result in the JSON format, and 200 would be a response status code.
REST API Architecture
Even though REST is not the best choice when performances are essential, we can do a few things here, such as caching, pagination, payload compression, and more.
In his doctoral dissertation, computer scientist Roy Fielding introduced and defined the term representational state transfer in 2000.
The REST constraints tell us to design APIs according to HATEOAS (Hypertext as the Engine of Application State). The Richardson Maturity Index rates APIs according to the fulfillment of these constraints and assigns the highest rating (level 3) to implement the HATEOAS ideas properly.
So, according to the Richardson Maturity Index, how do proper HATEOAS APIs at Level 3?
HATEOAS is all about constructing the API response: which information to put in and which information to link. You need responses that link to different resources: images, links, and other APIs. With the REST/HATEOAS design, the callers already get a link that can be used to get information. The callers don’t need to know how to construct the URL to get more information; it is already prepared. Just call it.
API Maturity Model
What is OData?
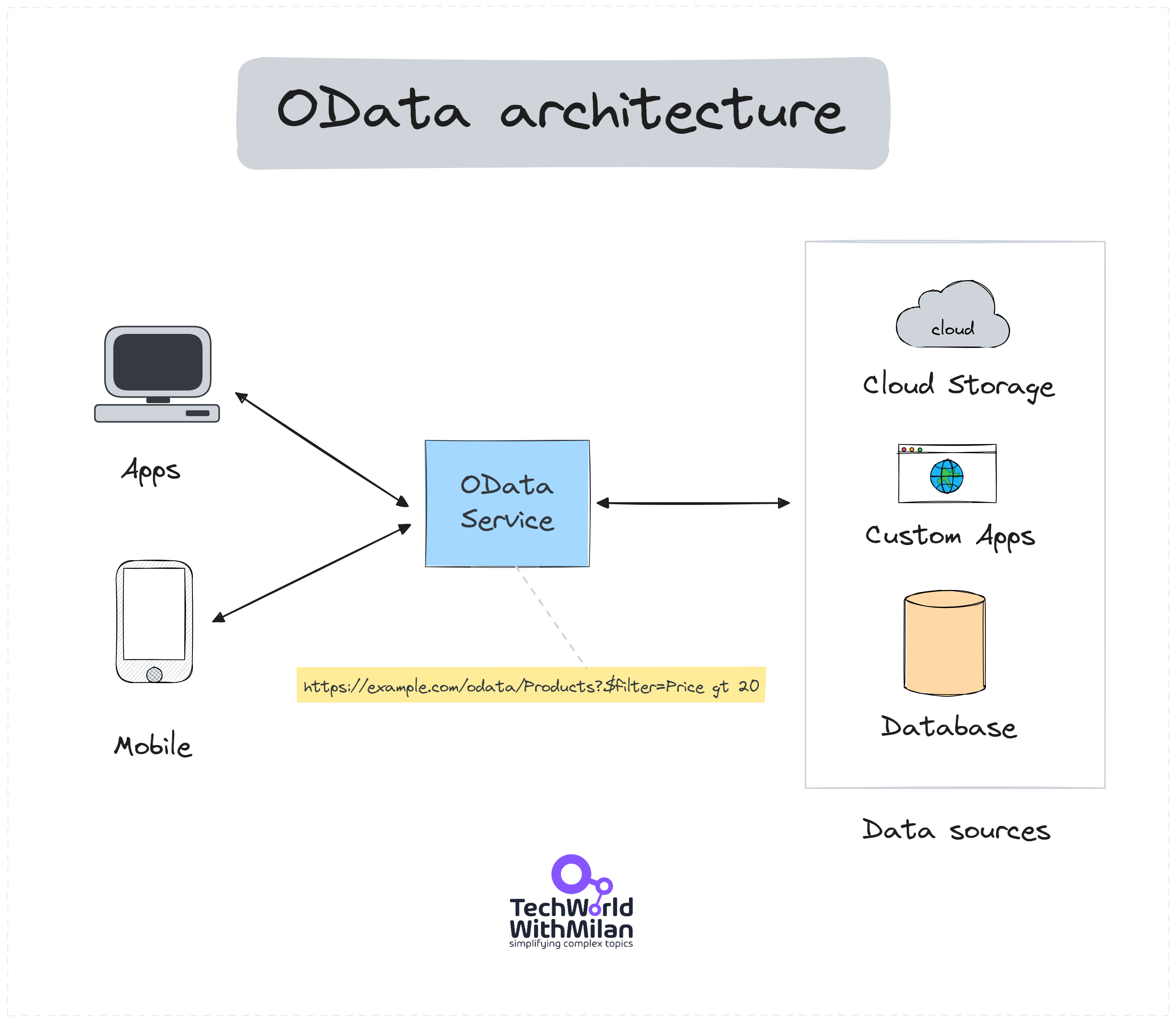
OData (Open Data Protocol) is an open standard for building and consuming RESTful APIs to facilitate data interchange. It uses HTTP for data communication and allows CRUD (Create, Read, Update, Delete) operations on resources represented in JSON or XML format. Data is organized into "Entity Sets" collections (database tables). Each entity set contains individual data points called "Entities" (rows in a table).
The main advantage of OData is its standardization of RESTful APIs, offering a uniform way to query and manipulate data. It provides a rich set of query capabilities directly in the URL, allowing for complex querying, filtering, sorting, and paging without additional API implementation effort.
OData should use it for scenarios where we need to expose data to a wide range of potential consumers (developers, mobile apps, etc.), if the application needs to interact with data from various sources or perform complex queries directly via URL without implementing this on the server side, usually in the rapid development setup. It shouldn’t be used for performance-critical applications or when we don’t need to allow clients control over data querying.
OData defines specific keywords appended to URIs to manipulate data retrieval. These are called System Query Options (SQOs). Here are some common examples:
$filter: Filter results are based on conditions (e.g., get customers with an email containing "@contoso.com").
$orderby: Sorts results based on specific properties (e.g., order products by price ascending).
$select: Selects only specific properties of an entity (e.g., retrieve just name and category from products).
$top and $skip: Limits the number of returned entities (e.g., get the first 10 customers or skip the first 20 and retrieve the rest).
$expand: Retrieves related entities along with the main entity (e.g., get a customer with their associated orders).
For example, if we have a scenario where we have an OData service exposing data from a database of products, the base URL of the service might look like this: https://example.com/odata/Products.
Now:
A client would send a GET request to retrieve all products to that URL.
To filter products by price, the client might append a query option $filter=Price gt 20 to the URL, making it https://example.com/odata/Products?$filter=Price gt 20.
To select specific fields, such as the name and price of each product, you would use $select, resulting in https://example.com/odata/Products?$select=Name,Price.
The OData service's response would be a list of products matching these criteria, in JSON or XML format, containing only the requested properties.
What is GraphQL?
GraphQL is a query language for APIs released and open-sourced in 2015 by Meta. The GraphQL Foundation now oversees it. GraphQL is a server-side runtime environment that enables clients to request the data they need from an API. Unlike traditional REST APIs, which often require multiple requests to fetch different pieces of data, GraphQL allows you to specify all the data you need in a single request. The GraphQL specification was open-sourced in 2015.
Because GraphQL doesn't over- or under-fetch results when queries are sent to your API, it guarantees that apps built with GraphQL are scalable, fast, and stable. It also allows for combining multiple operations into a single HTTP request.
GraphQL APIs are organized in terms of types and fields, not endpoints. Using the GraphQL Schema Definition Language (SDL), you define your data as a schema. This schema serves as a contract between the client and the server, detailing precisely what queries can be made, what types of data can be fetched, and what the responses will look like.
Benefits of GraphQL:
Efficient data fetching: You only request the exact data you need, eliminating the issue of over-fetching or under-fetching that can happen with REST. This can significantly improve performance, especially for complex data models.
Flexible and declarative: GraphQL uses a schema that defines the available data and how to access it. This schema allows developers to write clear and concise queries that specify their exact data needs.
Single request for multiple resources: Unlike REST, which requires multiple API calls to fetch data from different endpoints, GraphQL allows combining queries into a single request for improved efficiency.
Versioning and Backward Compatibility: GraphQL schema changes can be implemented with versioning, ensuring existing clients aren't affected while allowing for future growth.
Drawbacks of GraphQL:
Complexity in query structure: While flexibility is a strength, writing complex GraphQL queries can be challenging and requires careful planning for readability and maintainability.
Caching: Caching data with GraphQL is generally more complex than REST APIs, which leverage built-in HTTP caching mechanisms.
Security: GraphQL exposes your entire data schema, so proper security measures are crucial to prevent unauthorized access to sensitive data.
Learning Curve: For developers unfamiliar with GraphQL, understanding the schema and query syntax involves a learning curve.
Error handling: If the library doesn't parse errors with a status of 200 in the response body, the client must use more intricate logic to handle them.
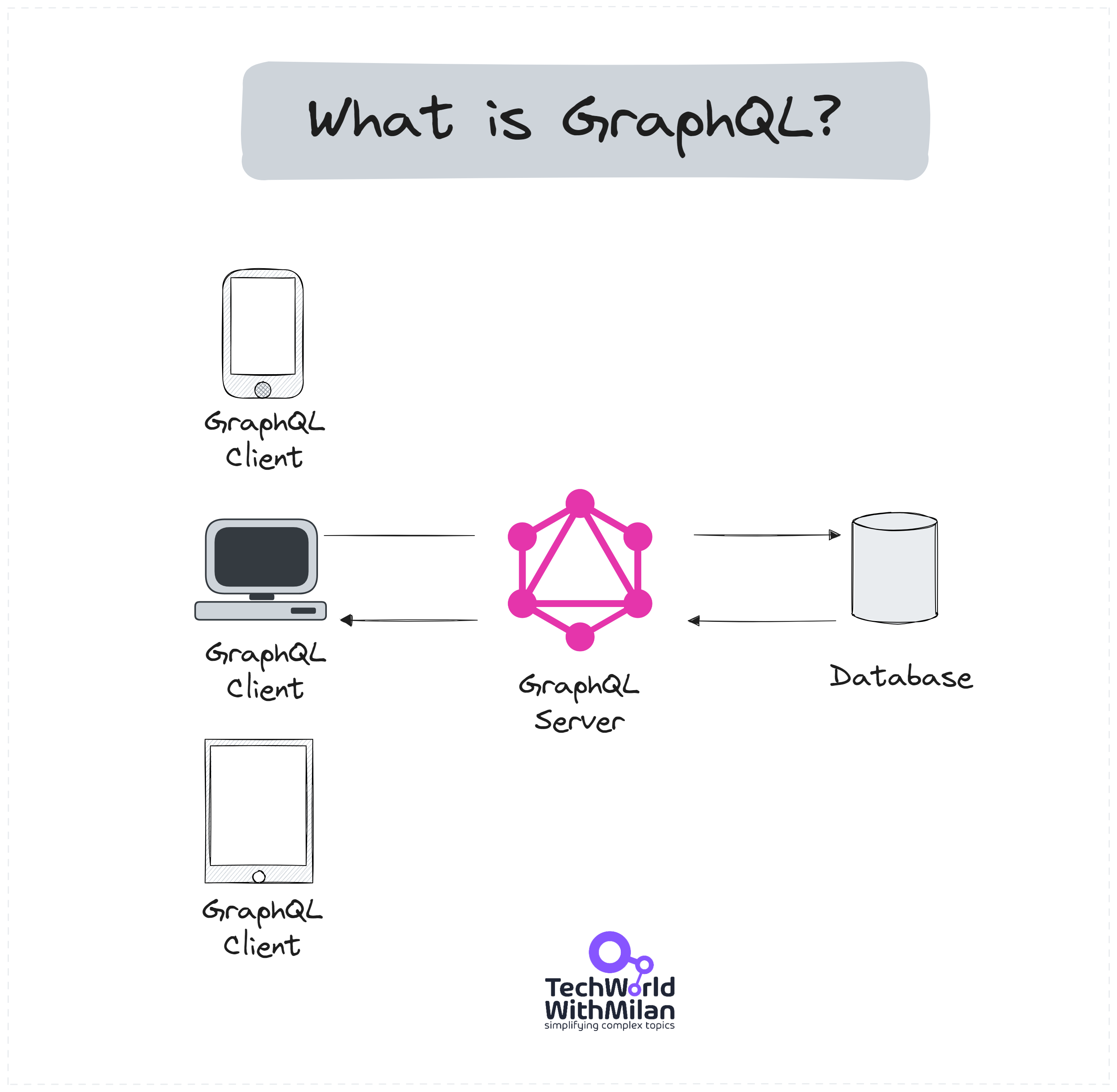
How it works:
The client defines a query in GraphQL syntax, specifying exactly how the data should be structured and what fields are needed.
The GraphQL server uses a predefined schema to determine the available data and its relationships to other data. This schema defines types, fields, and the relationships between types.
The server executes the query against the schema. For each field in the query, the server has a corresponding resolver function that fetches the data for that field.
The server returns a JSON object where the shape directly mirrors the query, populated with the requested data.
GraphQL API Architecture
GraphQL supports three core operations that define how clients interact with the server:
Queries: Used to retrieve data from the server. This is the most common operation used in GraphQL.
Mutations modify data on the server. This could involve creating new data, updating existing data, or deleting data.
Subscriptions are used to establish real-time communication between the client and server. The server can then update the client whenever the requested data changes.
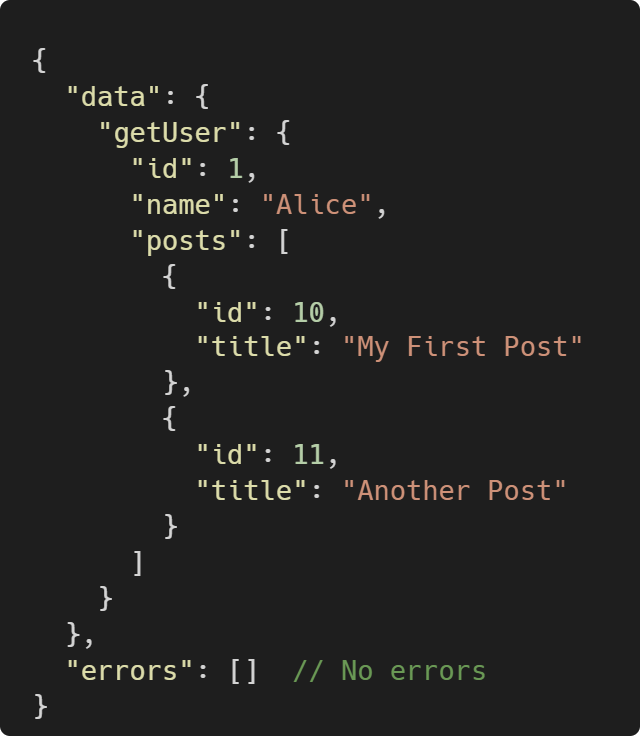
An example of a GraphQL request consists of an operation and the data you’re requesting or manipulating, e.g.
GraphQL request
This query retrieves data for a user with ID 1. It also fetches nested data for that user's posts, including their IDs and titles.
The response is a JSON object containing actual data requested by the query or mutation and optional errors.
JSON Response
To learn more about GraphQL, check the book “Learning GraphQL” by Eve Porcello and Alex Banks.
When should you use GraphQL, gRPC, and REST?
Developers can pick from a variety of client-server communication protocols when it comes to designing an application. Utilizing GraphQL, gRPC, and REST is relatively common in contemporary projects. Each protocol can provide various advantages depending on your application's requirements.
GraphQL is a flexible approach for making data requests that focuses on specific requests and provides only necessary ones. Its client-driven nature distinguishes it from other APIs. The client makes all the decisions instead of handling them. GraphQL’s advantages are that it is language agnostic, requests are made through a single endpoint, and strongly typed, as it has schemas.
REST is the most popular one. It is a great fit when a domain can be described as a set of resources. REST is a stateless architecture for data transfer. Its advantages include being a well-established standard, simple use, and good caching support.
gRPC is a lightweight and rapid system for obtaining data. Here, the primary distinction is how it describes its contract negotiations. It relies on contracts; the architecture is not what governs the negotiation; it is the relationship between the server and the client. While handling and calculations are delegated to a remote server housing the resource, most power is used on the client side. Its main advantages are that it has lightweight clients, is highly efficient, uses protocol buffers to send/receive data, and is open source, too.
The timeline of the most common API architectural styles is shown in the image below.
API Architectural Styles Timeline
So, when to choose each of those protocols:
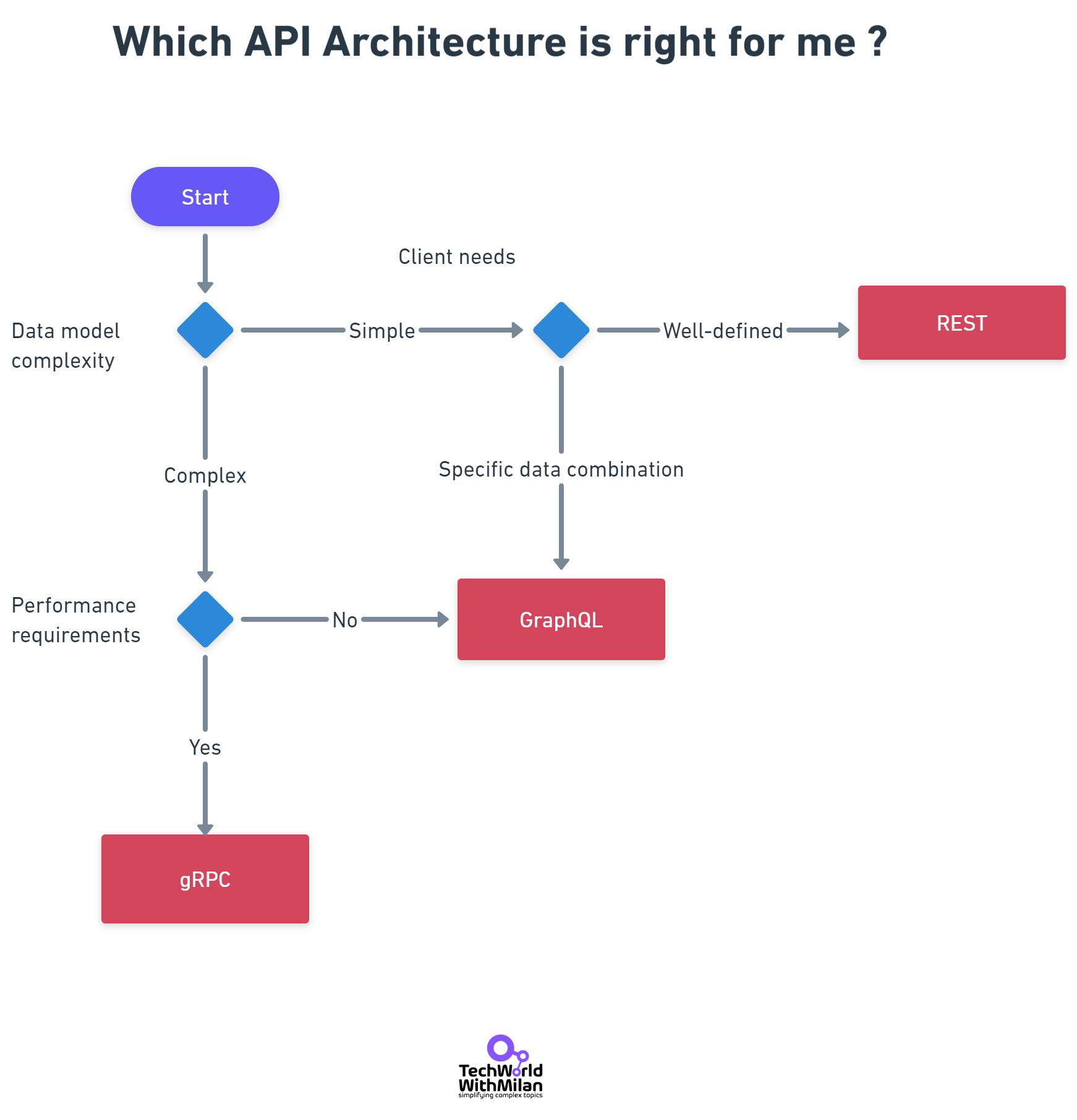
✅ Use REST if you're building a CRUD-style web application or you work with well-structured data. It's the go-to for public APIs and services that need to be consumed by a broad range of clients.
✅ Use gRPC if your API is private and about actions or if performance is essential. Low latency is critical for server-to-server communication. Its use of HTTP/2 and ProtoBuf optimizes efficiency and speed.
✅ Use GraphQL if you have an API that needs to be flexible in customizing requests and want to add data from different sources into an API. Use it in client-server communication, where we must get all the data on a single round trip.
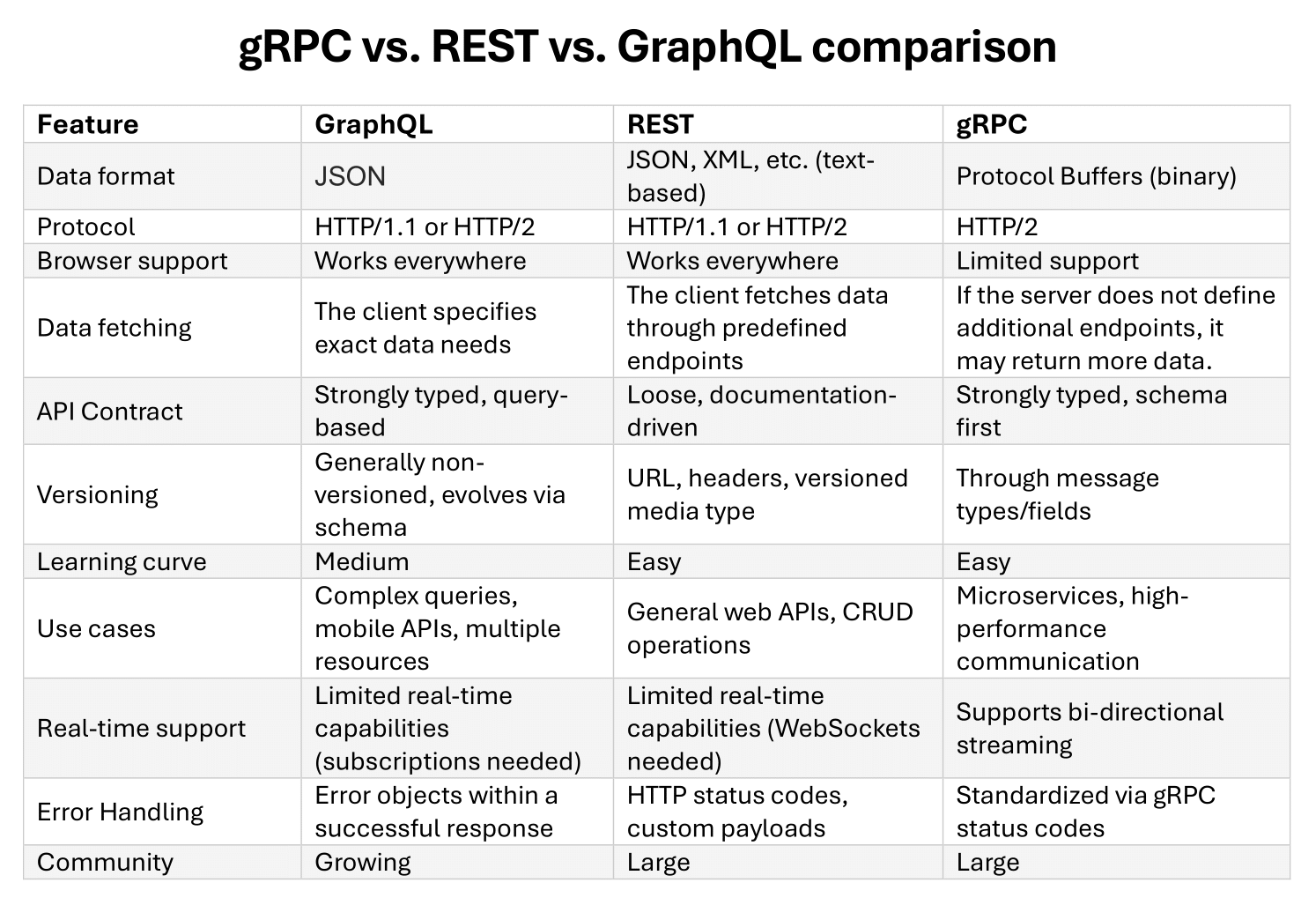
gRPC vs. REST vs. GraphQL comparison table
Also, a few more important aspects:
Scalability. Additional precautions are necessary because GraphQL may experience problems with graphs large enough to be under heavy stress. The cost of the REST API increases linearly with load and offers predictable performance within vertical restrictions.
Maintainability. Instead of versioning the API, developers must add new fields for modifications, which is backward incompatible with GraphQL and lacks versioning functionality. Dependency analysis is much more apparent with REST; you can see where each field originates.
Error handling. While using GraphQL, you will always receive a 200 response, and any retrieval problems will be recorded in the response's "errors" array. The client will need to undergo error parsing to comprehend what transpired. Before providing any information to the client, the REST API allows the developer to parse and respond on the backend if any fields are missing.
Which API Architecture is right for me?
As you can see, each of these choices has specific uses and benefits. Since there is no clear winner, what you should use—or, more importantly, what you want to use—depends on your objectives and strategy.
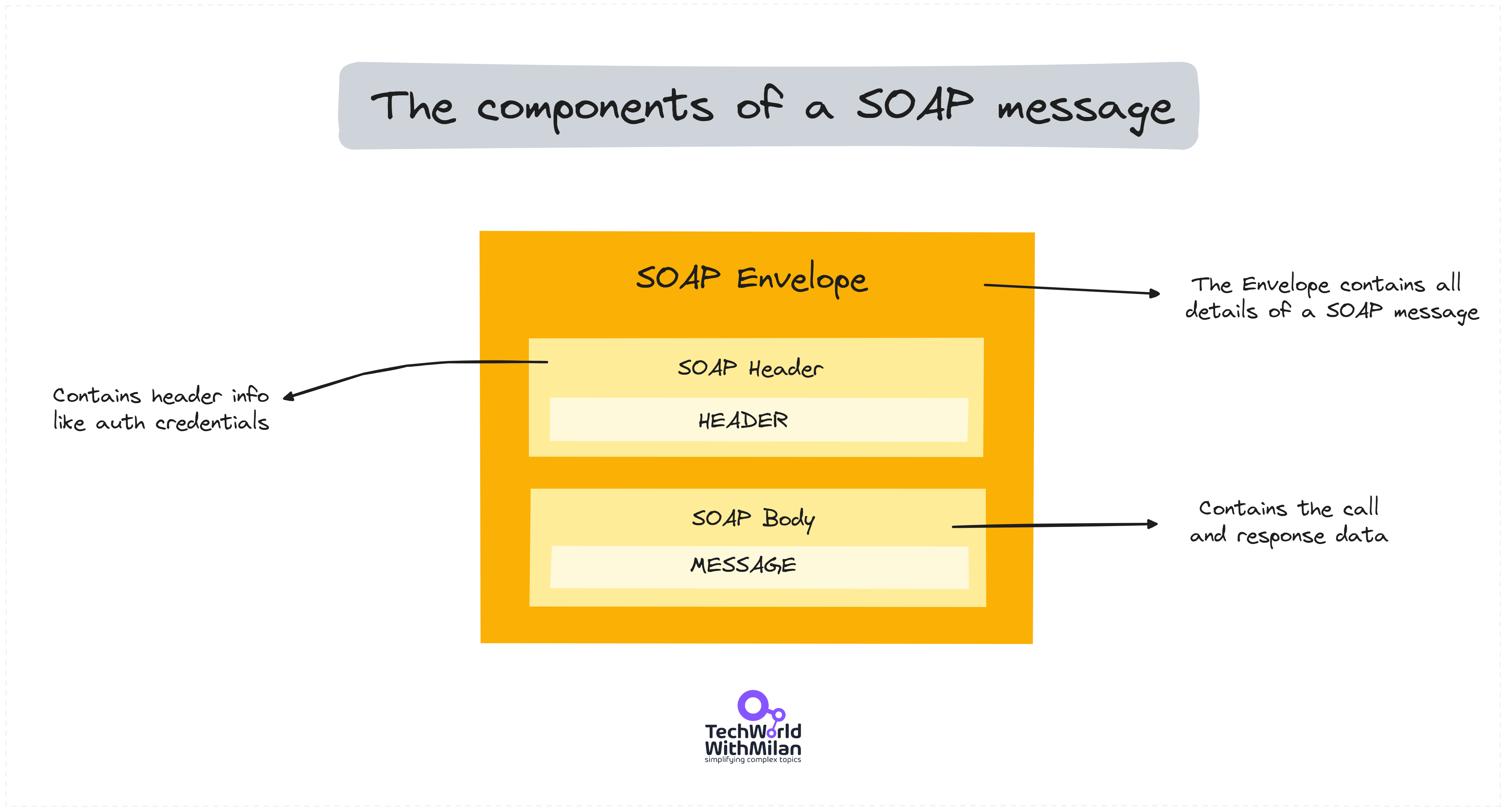
What happened to SOAP?
SOAP, or Simple Object Access Protocol, is a protocol designed for exchanging structured information in a web services platform-independent manner. It rose to popularity in the mid-2000s as a distributed communication protocol with many concrete implementations. SOAP was part of the WS—* families of protocols, which SOAP needed to build and send a message, but this was overkill for many. In the meantime, Microsoft started with WCF, and JSON started to replace XML. SOAP messages are XML-based and much larger than JSON ones. Due to the complexity and message size, usage started to decline slowly.
Yet, it is still used in some enterprise projects, as it supports WS-Security, a standard that includes features like encryption, integrity through digital signatures, and authentication over SSL. Also, SOAP is ACID compliance through WS-AtomicTransaction, which is critical in banking systems
BONUS: HTTP Status Codes Cheat Sheet
More ways I can help you
Patreon Community: Join my community of engineers, managers, and software architects. You will get exclusive benefits, including all of my books and templates (worth 100$), early access to my content, insider news, helpful resources and tools, priority support, and the possibility to influence my work.
1:1 Coaching:Book a working session with me. 1:1 coaching is available for personal and organizational/team growth topics. I help you become a high-performing leader 🚀.
Thanks for reading Tech World With Milan Newsletter! Subscribe for free to receive new posts and support my work.
Excellent and comprehensive article, Milan. I would recommend defaulting to REST, and making a switch only if you have an exceptional case. Personally, I'm not convinced that GraphQL's complexity is worthwhile, but maybe that's because I'm a fan of simplicity (for many reasons).
Thanks for writing this comprehensive article. I liked the section on which protocol to use when and I agree that GraphQL is quite suitable when one needs to combine data from multiple sources.









Excellent and comprehensive article, Milan. I would recommend defaulting to REST, and making a switch only if you have an exceptional case. Personally, I'm not convinced that GraphQL's complexity is worthwhile, but maybe that's because I'm a fan of simplicity (for many reasons).
Thanks for writing this comprehensive article. I liked the section on which protocol to use when and I agree that GraphQL is quite suitable when one needs to combine data from multiple sources.