
What I learned from the book Software Architecture: The Hard Parts

I recently read "Software Architecture: The Hard Parts" by Neal Ford, Mark Richards, Pramod Sadalage, and Zhamak Dehghani, and this is my review of it.
The book emphasizes the step-by-step approach of breaking down monolith, with different patterns for each step, and balancing tradeoffs for those patterns. The book is titled "Hard Parts," yet most of the book's concepts are already familiar in the industry, and maybe a “breaking monolith to microservices” title would be a better fit.

Throughout the book, the authors use the fictional story about the Sysops Squad to discuss architecture modularity, service granularity, distributed transactions, contracts, and more.
They also described some specific topics and patterns, such as component-based decomposition patterns, pulling apart operation data in a highly distributed architecture, reuse code patterns, managing workflows and orchestrations when breaking apart applications, transactional sagas, understanding complexities in breaking large monolithic applications, and making better decisions and effectively documenting them.
The things I liked about the book
Here are some things that I found valuable in this book, and they are located primarily in chapters 1 to 7 in the first part of the book, which is focused on breaking things apart. The book's second part brings different patterns for pulling things back together.
✅ Focus on tradeoffs
The most essential architectural skill is making decisions and balancing tradeoffs. On this topic, the book gives some advice on how to do a modern tradeoff analysis by using the following steps:
Find what parts are entangled together.
Analyze how they are coupled to one another.
Assess tradeoffs by determining the impact of change on interdependent systems.
They introduced the term quantum when analyzing how different parts are connected and communicating. In architectural terms, quantum represents “independently deployable artifacts with high functional cohesion, high static coupling, and synchronous dynamic coupling.” This can be one microservice.
In addition, the authors introduced static (how static dependencies resolve the architecture via contracts) and dynamic coupling (how quanta communicate at runtime).
"Don't try to find the best design in software architecture; instead, strive for the least worst combination of trade-offs"
✅ The main modularity drivers
A clear business objective is central to modularizing a system into smaller parts. This objective could be:
Speed-to-market is achieved by architectural agility, i.e., the ability to respond quickly to a change.
Scalability, where the need for more scalability support increased user activity
Fault tolerance is an application's ability to fail and continue to operate.
✅ Breaking down the monolith
The authors proposed two methods:
Component-based decomposition (if monolith is modular): It applies different refactoring patterns for extracting components to form an incrementally distributed architecture. A component is a well-defined application block with a clear responsibility (e.g., in a namespace or directory). The process involves identifying and sizing components, over-gathering common domain components, and flattening them to create component domains and services. An essential element here is sizing components, and it’s done by calculating the total number of statements with a given component—the ideal size of 1 to 2 standard deviations from the average component size.
Tactical forking (if the monolith is a big ball of mud): copy the whole monolith and remove the unnecessary parts. We build a proxy with old and new (forked) applications and two teams. Each team has an exact copy of the codebase and then starts to delete the code they don’t need. Ultimately, the goal is to have precise components in the forked application. This is much easier than extracting components with many dependencies.
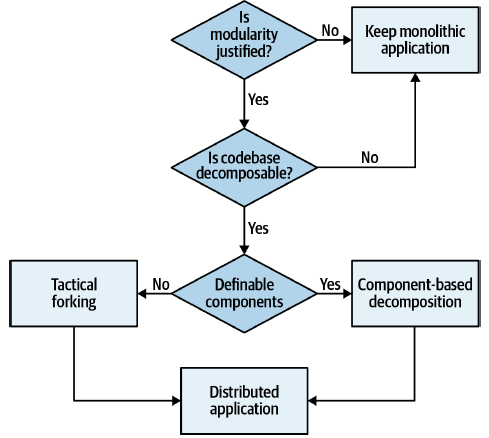
✅ Service Granularity
While modularity concerns breaking up systems into different parts, granularity deals with the size of these parts. The authors focus on determining the right granularity level (component size). The metric for the granularity of components is the number of statements in a service and the number of public interfaces exposed by a service.
Also, they provide some granularity desintegrators, which are justifications for when to break service into smaller pieces:
Service scope and function. Here, we need to consider cohesion and size directly related to the single responsibility principle (from SOLID), where each service should be aligned with its responsibility, i.e., to do one thing well.
Code volatility. Consider splitting a component that changes more frequently than the rest to reduce the scope of testing and deployment.
Scalability and throughput. Consider this if some services need to scale more than others.
Fault tolerance. If one component crashes, this can impact other components.
Security. If we need to have different security concerns per component.
Extensibility. If a new service would be a better fit.
Conversely, we have granularity integrators, which work oppositely; they justify when to put services back together. The main drivers for integration are:
Database transactions. Suppose we need an ACID transaction between two services.
Workflow and Choreography. If services communicate too much with one another, they become less fault-tolerant and performant.
Shared Code. If we have multiple services that use the same shared library, if a change occurs in the library, we would need to change all services.
Data Relationships. Suppose we have data that belongs to a bounded context tightly coupled to the service.
✅ Different kinds of valuable patterns
The book's second part, which is mainly focused on putting things back together, reveals some interesting patterns.
Code reuse patterns. In this group, we have different kinds of code reuse patterns:
Code replication. Shared code is copied into each service, e.g., when we have a simple static code (annotations, attributes, etc.).
Shared library: This approach is good for low- to moderate-change shared code environments. We need to have fine-grained, versioned libraries.
Shared Services are a common approach to addressing shared functionality, and they should be used in polyglot environments when shared functionality tends to change frequently. However, they are less performant and scalable than shared libraries.
Sidecars and service mesh. They are good choices when we have cross-cutting concerns.
Distributed transactions. They occur when we have requests containing multiple updates by different services, and they don’t support ACID properties. Here we have the following patterns:
Background synchronization. Used when we have independent services that periodically change data sources and keep them in sync.
Orchestrated request-based. When one service is in charge of making synchronous requests to other services.
Event-based pattern. When we need to have pub/sub-messaging models to post events to a topic or event stream.
Data access patterns. These patterns mainly discuss accessing data broken into separate databases or schemas owned by different services. Here, we have other patterns:
Inter-service calls are used when one service needs to ask another for the data it needs. This simple pattern has many disadvantages, including networking, scalability, security issues, and the inability to be fault-tolerant.
Column schema replication. Here, we keep a local copy of other service data. It has good performance but could have data consistency issues.
Duplicate caching pattern. It is similar to the previous pattern, but we keep data in memory here. It allows good performances and fault tolerance but is unsuitable for high data volumes.
Data domain pattern. This pattern uses a shared database with joint ownership between services. It has good performance and fault tolerance, but dealing with data ownership and security is challenging.
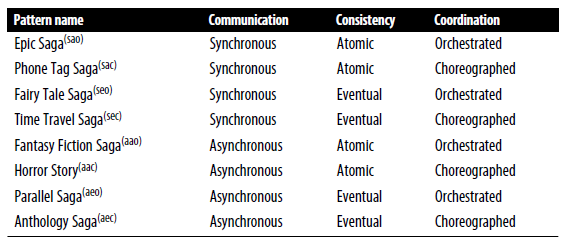
Transactional sagas. A saga is a sequence of local transactions that trigger the next update. The book considers the following sagas:
Epic. The traditional one is called the Orchestrated Saga, as it has a coordinator. It uses synchronous communication and mimics the monolithic system. It’s best to avoid it.
Phone Tag. It is similar to the Epic saga but without a coordinator. It is more complex. It is better for simple workflows that don’t have many common error conditions.
Fairy Tale. Here, we have an orchestrator to coordinate requests, responses, and error handling, but it is not responsible for managing transactions done by domain services. This pattern appears in many microservice architectures.
Time Travel. It uses synchronous communication and eventual consistency but a choreographed workflow (no central mediator). This pattern can implement the Chain of Responsibility design or the Pipes and Filters architecture style.
Fantasy Fiction. This pattern uses atomic consistency, asynchronous communication, and orchestrated coordination. It is used to improve Epic Saga's performance, but it usually fails because synchronicity adds more complexity to the architecture around coordination.
Horror story. This pattern uses asynchronous communication, atomic consistency, and choreographed coordination. It’s a horrible combination because it combined coupling around the atomicity of the two loosest coupling styles, asynchronous and choreography.
Parallel. This pattern uses a mediator, suitable for complex workflows but uses asynchronous communication for better performance.
Anthology Saga. It uses asynchronous communication, eventual
consistency, and choreographed coordination, which means it uses message queues to send asynchronous messages to other services without orchestration. It doesn’t work well for complex workflows around resolving data consistency errors.
The things I missed in the book
There are a few things I would expect to have in such a book, namely:
❌ Limited code examples. While the book offers conceptual understanding and practical patterns, it could benefit from more concrete code examples. Showing real-world implementations of the discussed concepts would further solidify the learning experience.
❌ No real-life examples. The book follows Sysops SAGA's fictional story, whereas a real-life example would be more worthwhile. In this way, some things would sound artificial or forced.
❌ Limited scope on non-distributed topics. While distributed architectures are crucial, neglecting other aspects like security, performance, and scalability creates a somewhat incomplete picture. Architects often need to juggle these considerations alongside distribution, and the book could benefit from including dedicated sections on them.
❌ No structured approach. I missed the structured approach. It started well with essential concepts, such as modularity and decomposition, and then twelve immediately into components and pulled apart data. Then, it went to service granularity and reuse patterns and data ownership and access patterns later.
❌ Limited discussion of alternative paradigms. The book primarily focuses on microservices and related distributed architectures. While this is a dominant trend, exploring alternative paradigms like serverless architectures or event-driven design could provide a more balanced perspective.
The book is a good resource for software architects and engineers interested in the complexities of distributed systems from a theoretical standpoint. However, readers should know its limitations, such as the lack of detailed code examples and potentially overwhelming depth for beginners.
👍 Recommendation
As a summary of this book, I would recommend it to:
Software architects and engineers working with distributed systems
Developers interested in building and maintaining complex software applications
Technical leads and managers responsible for making architectural decisions
It is an excellent companion to the book "Monolith to Microservices," by Sam Newman.
It's important to note that the book might be less suitable for:
Beginners with limited experience in software architecture
Individuals seeking in-depth knowledge of specific technologies
Those looking for a prescriptive "how-to" guide for building distributed systems
More ways I can help you
Patreon Community: Join my community of engineers, managers, and software architects. You will get exclusive benefits, including all of my books and templates (worth 100$), early access to my content, insider news, helpful resources and tools, priority support, and the possibility to influence my work.
Sponsoring this newsletter will promote you to 41,000+ subscribers. It puts you in front of an audience of many engineering leaders and senior engineers who influence tech decisions and purchases.
1:1 Coaching: Book a working session with me. 1:1 coaching is available for personal and organizational/team growth topics. I help you become a high-performing leader 🚀.
Great book review! Succinct, to the point, and informative. It does pique me to read the book while also getting an overall idea of the book. The list on "The things I missed in the book" section is great as they provide topics that could make the book even more useful. Perhaps they'll be part of your subsequent books or whichever media you're going to provide.
Thanks for the great post!
Thanks for sharing it, Milan.
This post is the kind of entry point someone should read before diving into a thick book.
It's also a good refresher. I read (tried at least 😅) this book when it was pretty advanced for me.
But rather than going again through the whole book, between my notes and your post, I get a better understanding than in the first read.