
The Trends #11: AI agents still can't build software from scratch

The Trends filter tracks tech trends: what moved, why it matters, and what to watch next. If you spot a signal I missed, reply with a link and one line of context.
Today, we cover:
Does AI-powered coding trade speed for technical debt. Carnegie Mellon tracked 806 open-source repositories after adopting Cursor. The speed boost disappeared in three months, but the bad code stayed.
ThoughtWorks Technology Radar, Volume 34. Claude Code moves to Adopt. MCP by default lands in Caution. Same edition. The rest of the Radar is about agents, how to secure them, how to keep them on a leash, and the cognitive debt they leave behind.
AI agents still can’t build software from scratch. ProgramBench gave 9 frontier models a compiled binary plus docs and asked them to rebuild the program. 1,800 runs, zero tasks solved end-to-end.
Half our code is now AI-generated. Most of us think we’re in a bubble anyway. AI-written code went from 28% to 54% in a year, and 70% of developers in the State of AI 2026 survey still call this a bubble. The heaviest users are the biggest skeptics.
What do people actually use AI for at work. Microsoft went through 100,000+ Copilot chats. People don’t use it for emails and summaries, but to think.
So, let’s dive in.
Review the actual change, not the file list (Sponsored)
AI writes more code than ever. Reviewing it shouldn’t mean scrolling forty files in alphabetical order.
CodeRabbit Review reorganizes any pull request from a flat file list into a structured, layer-by-layer walkthrough - the logical reading order of the change, not the order your platform happens to sort it. Every range gets its own plain-language summary, with sequence diagrams, state machines, and ERDs generated inline wherever a visual earns its place.
Open it straight from the Review Change Stack button in the PR Walkthrough. Navigate cohorts and layers with the keyboard, comment on exact line ranges, and submit native reviews, comments, and approvals directly to GitHub or GitLab, where your team expects them.
In early access, available for free to everyone.

1. Does AI-powered coding trade speed for Technical Debt
Developers report 10x productivity gains from AI coding agents, yet a Carnegie Mellon study of 806 open-source GitHub repositories found something a bit different.
Researchers compared Cursor-adopting projects with 1,380 matched control repositories, tracking monthly code output and quality using SonarQube.
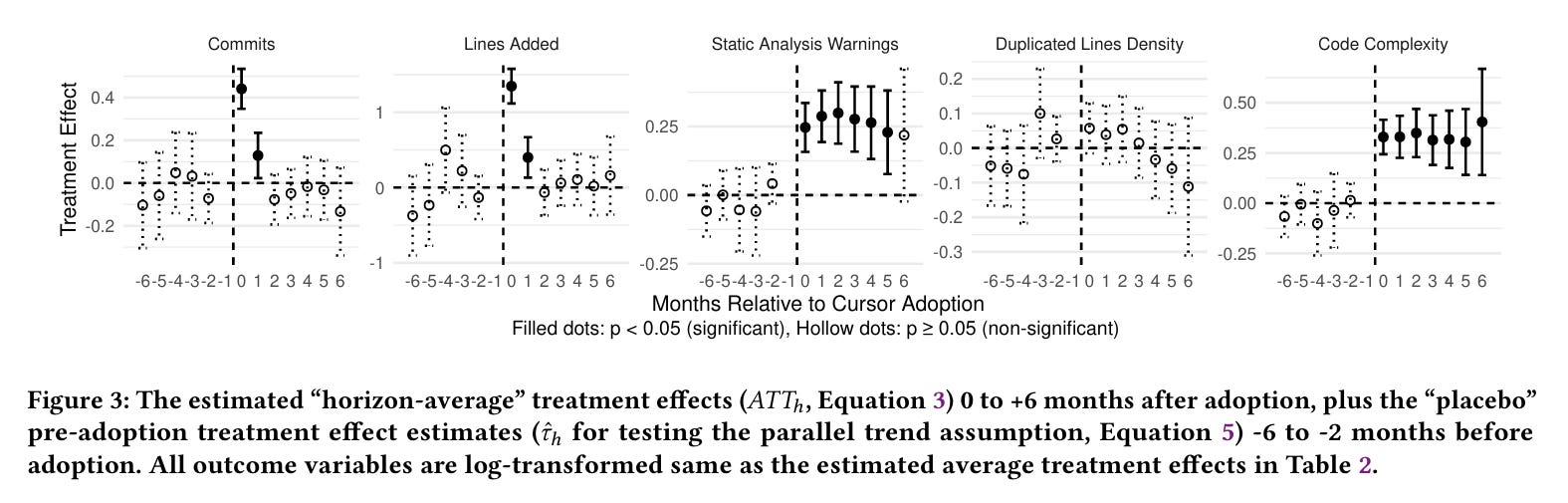
Here are the key findings:
1. The velocity boost is real but disappears fast
Projects saw a 281% increase in lines added and a 55% increase in commits during the first month after Cursor adoption. By month three, both metrics dropped back to pre-Cursor levels. The spike looks great on a dashboard. It just doesn’t last.
2. Technical debt accumulates and stays
Static analysis warnings rose by 30% and code complexity increased by 41% on average. This decline in quality persisted throughout the project.
3. That debt creates a self-reinforcing slowdown
The researchers found a feedback loop between quality and velocity. A 100% increase in code complexity caused a 64.5% decrease in future development velocity. A 100% increase in static analysis warnings caused a 50.3% drop in lines added. The two-month speed boost generates enough technical debt to drag down productivity for months afterward.
4. AI writes more complex code than humans
Regardless of the codebase’s size, Cursor-adopting projects still had 9% higher code complexity than comparable projects producing the same volume of code. This means that such projects are harder to maintain.
QA has to keep up with higher output. We can say that teams adopting agentic coding tools without upgrading their processes are borrowing speed from the future.
The paper even suggests that tools should consider “self-throttling,” reducing the volume of suggestions when project complexity crosses healthy thresholds.
Lines of code produced are not the same as progress made
2. ThoughtWorks Technology Radar - Volume 34 (April 2026)
Two big shifts in this edition: Claude Code moved to Adopt, and MCP by default moved to Caution. Both in the same Radar.
The rest of Volume 34 is about agents, with warnings sharper than V33.
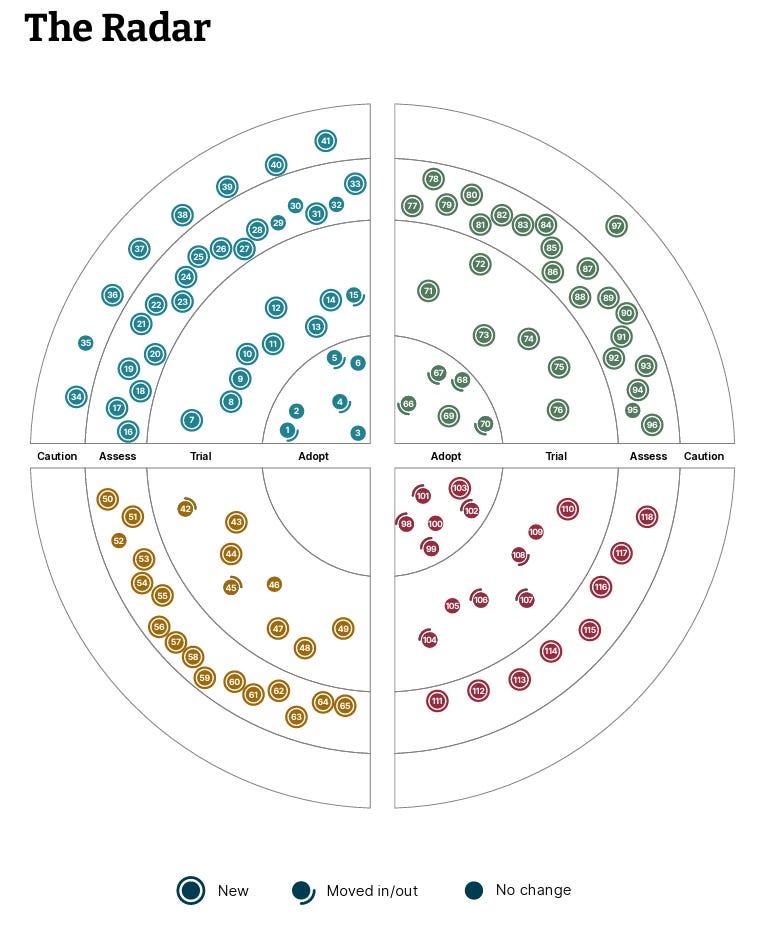
Four themes stand out:
Evaluating tech is getting harder
Semantic diffusion is part of it. Terms like spec-driven development and harness engineering are used inconsistently, often before their meanings have settled.
The pace makes it worse. Some tools ThoughtWorks reviewed were less than a month old and were often maintained by a single contributor working with a coding agent.
The bigger risk is cognitive debt in the codebase: as more code is generated by AI, teams adopt solutions without building the mental models needed to debug them later.
Retaining principles, relinquishing patterns
AI is pushing teams back to the foundations: pair programming, mutation testing, DORA metrics, zero trust architecture. After years of being abstracted away in the name of usability, the terminal is back as a primary interface.
But not everything carries over. Team topologies will need to evolve into agent topologies, and feedback cycles will need to be rethought.
Securing permission-hungry agents
The agents worth building are the ones that need access to everything. OpenClaw and Claude Cowork supervise real work tasks. Gas Town coordinates agent swarms across entire codebases.
Simon Willison’s “lethal trifecta“ describes an unsafe agent: private data, untrusted content, external action. That now describes most useful agents by default, not by misconfiguration.
Zero trust, least privilege, defense in depth. All table stakes. Safe agent systems will be pipelines of constrained agents, not monolithic ones.
Putting coding agents on a leash
As coding agents get better, humans are tempted to step out of the loop. Teams are pushing back with coding agent harnesses.
Feedforward controls, such as Agent Skills, modularize instructions and load them just in time. Spec-driven frameworks like GitHub Spec-Kit and OpenSpec structure planning, design, and implementation.
Feedback controls wire deterministic quality gates into agent workflows: compilers, linters, type checkers, mutation tests. Failures trigger auto-correction before human review.
In more detail:
Techniques:
✅ Adopt: Context engineering, Curated shared instructions, DORA metrics, Passkeys, Zero trust architecture
🧪 Trial: Agent Skills, Feedback sensors for coding agents, Mutation testing, Progressive context disclosure, Sandboxed execution for coding agents
🛑 Caution: Agent instruction bloat, Codebase cognitive debt, Coding agent swarms, MCP by default, Pixel-streamed development environments
Platforms:
🧪 Trial: AG-UI Protocol, AWS Bedrock AgentCore, Graphiti, Langfuse, Replit, SigNoz 🔍 Assess: ClickStack, Coder, MCP Apps, Sprites
Tools:
✅ Adopt: Axe-core, Claude Code, Cursor, Kafbat UI, mise
🧪 Trial: cargo-mutants, Claude Code plugin marketplace, Dev Containers, Figma Make, OpenAI Codex
🛑 Caution: OpenClaw
Languages and Frameworks:
✅ Adopt: Apache Iceberg, Declarative Automation Bundles, React JS, React Native, Svelte, Typer
🧪 Trial: Agent Development Kit, DeepEval, Docling, LangExtract, LangGraph, LiteLLM
3. AI agents still can’t build software from scratch
Meta, Stanford, and Harvard just released ProgramBench, which hands an agent a compiled binary plus its docs and asks it to rebuild the program from scratch. They tested 9 frontier models on 200 tasks, from small CLI utilities to FFmpeg, SQLite, and the PHP interpreter.
Across all 1,800 runs, no model solved a single task end-to-end.

Here is what the data shows:
The best model passed 95% of tests on only 3% of tasks
Claude Opus 4.7 hit that 3% mark, with Opus 4.6 close behind at 2.5% and Sonnet 4.6 at 1.6%. Every other model scored zero, including GPT 5.4 and Gemini 3.1 Pro.
The benchmark runs on 248,853 behavioral tests.
Models write monolithic code, not modular code
60% of model solutions live in 1-3 files. Median directory depth is 1, against 2 for the human-written code. Models keep 10-29% of the original function count and make each one 1.08x to 1.62x longer.
We tell engineers to break code into small, focused functions, but models go the other way.
Models often abandon the reference language for Python
Models stick with the original language only 50% of the time. Python wins overall at 36% of runs. GPT 5.4 picks Python 79% of the time, even when the original is Rust or C/C++.
Some models write code in one shot, others iterate
GPT 5.4 writes 96% of its final code in one turn. Sonnet 4.6 takes the opposite path: 868 commands and 18.3 file edits per task on average. Neither approach produces a working program.
C/C++ projects are the hardest
C/C++ tasks land at an average pass rate of 27.7%, compared to 38.5% for Rust and 38.4% for Go. FFmpeg, php-src, and DuckDB stay unsolved. The wins are on smaller tools like nnn, jq, and gron.
Agents can patch existing code, yet building it from scratch is a different problem entirely.
4. Half our code is now AI-generated. Most of us think we’re in a bubble anyway.
7,258 developers answered the State of AI 2026 survey. Adoption is rising, which is not surprising. The interesting part is that the people leaning in hardest are the same ones who think the whole market’s overheated.
Here are the four that stuck with me:
AI-generated code doubled in a year
The average chunk of code that’s AI-written went from 28% in 2025 to 54% now. The 75%+ crowd grew fastest. And the number of people who say they’re on AI “constantly” just doubled too. This stopped being an early-adopter thing.
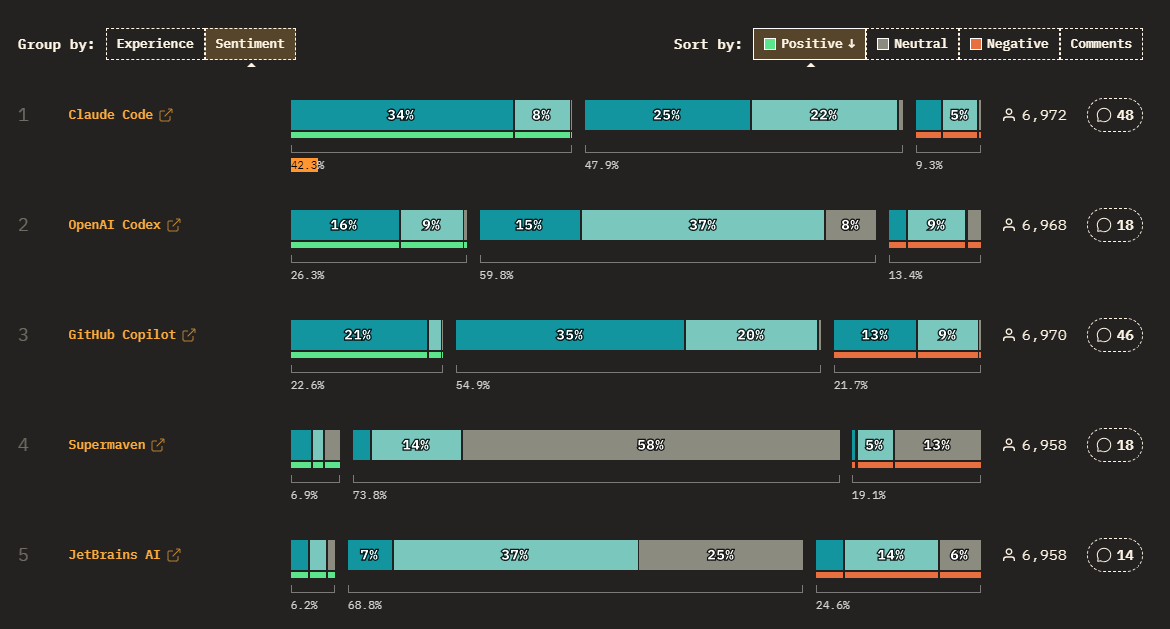
Claude Code leads, and agents are why
Claude Code took the top spot for positive sentiment among coding agents at 42.3%, ahead of OpenAI Codex (26.3%) and GitHub Copilot (22.6%). Agents are quietly eating the old chatbot-and-app-generator workflow, and the wallets followed. ChatGPT’s still the most popular model overall, but Claude is the one people actually pay for: 4,592 respondents to ChatGPT’s 3,261.
The bubble call is consensus now
About 70% of respondents agree or strongly agree we’re in an AI bubble right now. The cheap, VC-subsidized era is winding down, and personal AI spend keeps climbing as the labs raise prices. So we’re paying more while betting the valuations won’t hold.
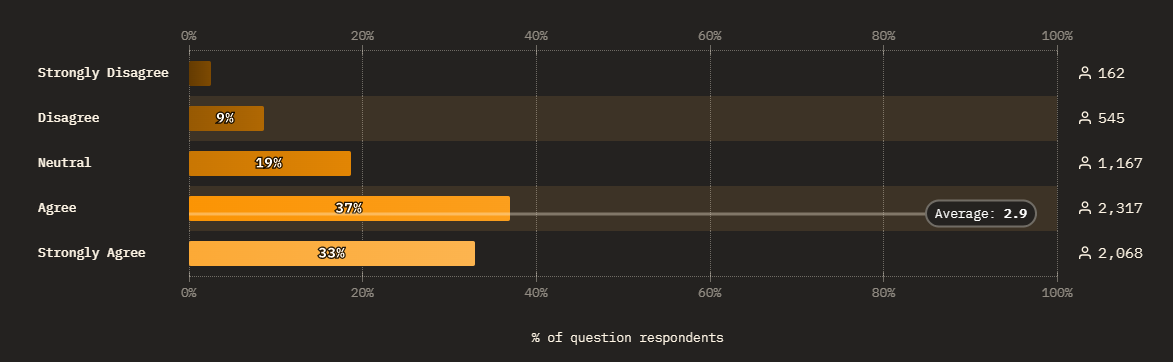
Hallucinations are still the daily headache
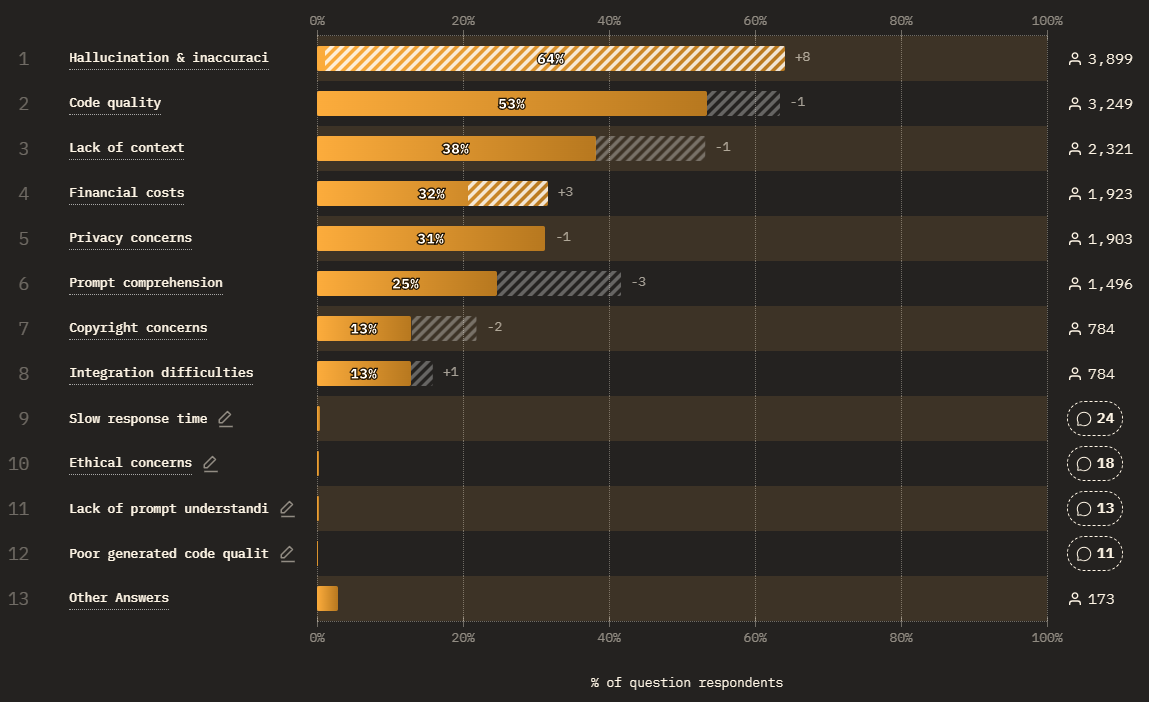
The top pain point is hallucinations and inaccuracies (3,899 responses), the biggest climber on the list this year, with code quality right behind. On risks, job displacement and military use of AI top the list. We’re handing these tools more of the work and trusting their output less.
5. What Do People Actually Use AI for at Work?
We assume people mostly use AI for emails and for summarizing meetings. Microsoft classified over 100,000 Copilot chats for its 2026 Work Trend Index and found something different: people use AI to think.
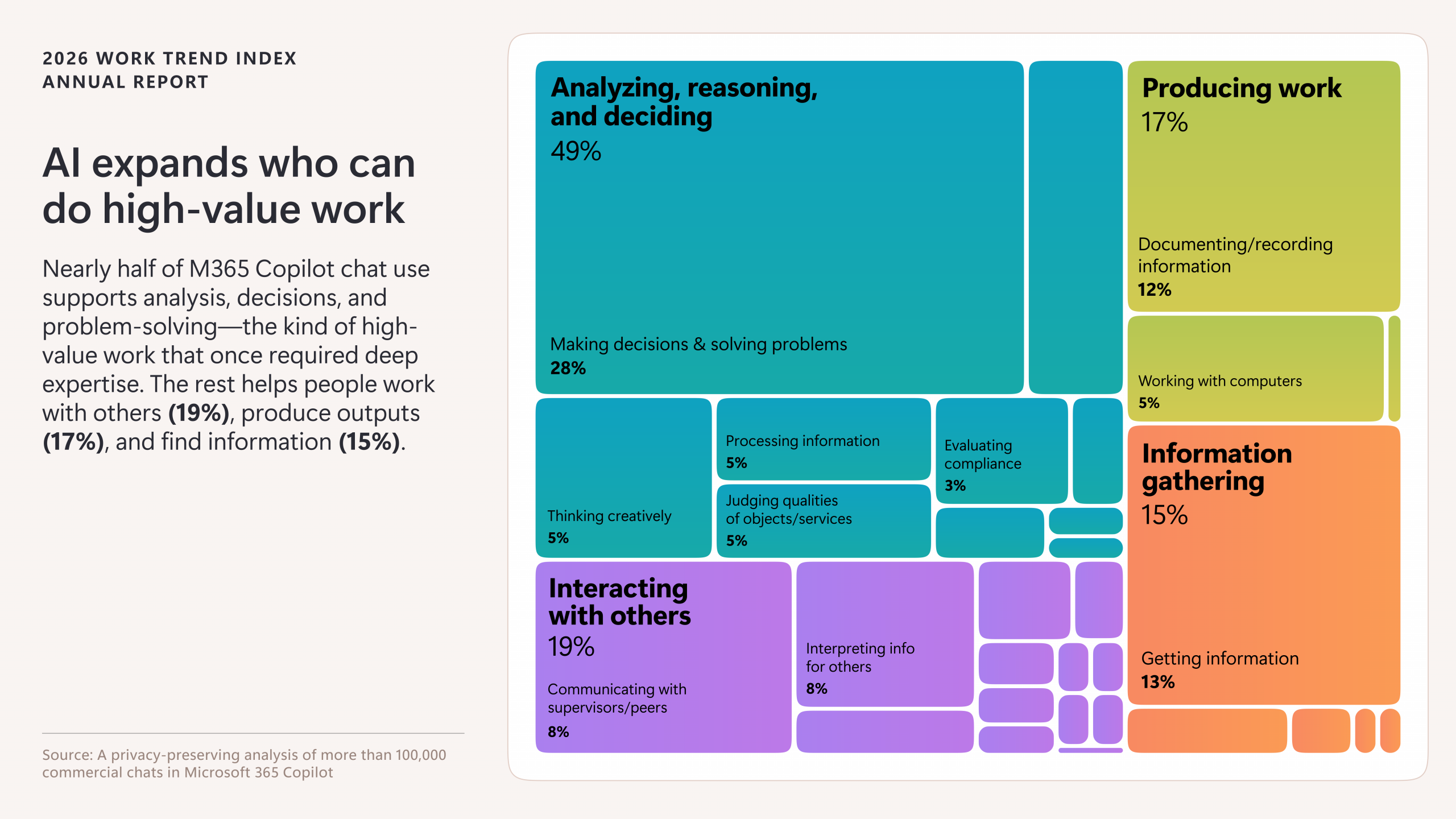
Here is what the data shows:
Half of all usage is cognitive work
49% of Copilot use supports analyzing, reasoning, and deciding. Making decisions and solving problems alone accounts for 28%.
The rest is split among interacting with others (19%), producing outputs (17%), and finding information (15%).
People reach for AI for judgment. These numbers measure shares of classified user goals, not time spent.
The skill premium is shifting
Asked which human skills matter more as AI takes on work, users put quality control of AI output first at 50% and critical thinking second at 46%.
And 86% say they treat AI output as a starting point, not a final answer. The job moves from generating answers to evaluating and owning them.
The ceiling is rising
58% of surveyed AI users say they now produce work they couldn’t do a year ago. Among the most advanced users, the ones who build multi-agent workflows and redesign processes around AI, that number hits 80%.
This group also deliberately works without AI on some tasks to keep their skills sharp, 43% vs 30% for everyone else.
The bottleneck is not the people
Microsoft tested 29 factors with AI impact. Organizational factors like culture, manager support, and talent practices have more than 2x the impact of individual mindset and behavior, 67% vs 32%.
Yet only 26% of users say their leadership is aligned on AI, and just 13% say they’re rewarded for redesigning work with AI even when the results don’t land.
The capability sits with individuals, but the constraint sits with the organization.
AI inherits the infinite workday
Microsoft’s earlier report shows what AI gets dropped into: 117 emails a day, 153 Teams messages, and a reported interruption every 2 minutes during core hours. Without redesigning how work flows, AI speeds up the chaos instead of fixing it.
The pattern across both reports is the same: the technology and the people are ahead, and the organization is the constraint.
📔 My book Laws of Software Engineering is out
This book started as a private note. In 20+ years in tech, I watched the same failures repeat at different companies, with different technologies and different teams, so I wrote down what I saw. Gall’s Law came from a project that never worked. Brooks’ Law from a team that grew but got slower. Goodhart’s Law dates back to a time when we hit every goal, yet the results still got worse.
Later I met engineers who figured out the same things, almost always the hard way: a failed project, a burned-out team, a codebase nobody wanted to touch. That is how most of us learn these lessons, because nobody teaches them. And that way costs a lot.
The book collects them. 56 laws across architecture, people, time, quality, scale, code, and decision-making. Each chapter explains what the law says, where it comes from, when it applies, and how it shows up in a real project. Many chapters add related ideas like the Two-Pizza Rule, the Cobra Effect, and Impostor Syndrome.
Keep it at your desk and open it when something in your project feels wrong.
Forewords by Dr. Rebecca Parsons, CTO Emerita at Thoughtworks, and Addy Osmani, Engineering Director at Google Cloud AI. Reviewed by 20 engineers and leaders from Google, Amazon, Uber, Oracle, Yelp, Nutanix, and CodeScene.

Want to advertise in Tech World With Milan? 📰
If your company is interested in reaching founders, executives, and decision-makers, you may want to consider advertising with us.
Love Tech World With Milan Newsletter? Tell your friends and get rewards.
Share it with your friends by using the button below to get benefits (my books and resources).